Executive Summary
- AI의 대화 이해는 단순 텍스트 처리에서 발전해 문맥(Context), 의도(Intent), 의미(Semantics)까지 해석하는 단계로 진화
- 인간 대화는 불완전하고 모호하며 암묵적 의미가 많기 때문에 AI는 단어가 아닌 관계와 맥락 중심으로 이해해야 함
-
핵심 기술 요소
- 자연어 이해(NLU) 및 의미 분석
- 문맥 유지(Context Tracking)
- 의도 파악(Intent Recognition)
- 최신 AI는 단순 질문 응답을 넘어 대화 흐름을 유지하고 연속적인 상호작용을 처리
- 향후 방향은 인간과 유사한 수준의 대화 이해 및 상황 인식 능력 강화
- 핵심 메시지 : “AI의 경쟁력은 단순한 언어 처리 능력이 아니라 맥락과 의도를 이해하는 ‘대화 이해 능력’에 있다.”
병렬 처리 혁명에서 시작된 생성형 AI
AI는 어떻게 사람의 언어를 이해하고 답변도 하는 것일까요? 이에 대해선 생성형 AI 열풍이 시작된 지 어느덧 3년이 다 되어 가기 때문에, 관심이 있으셨던 분들이라면 이 마법 같은 AI는 Transformer 아키텍처라는 것에 기반하고 있다는 것은 들어보셨을 겁니다. 그렇다면 이 Transformer라는 것은 무엇일까요? AI를 사용하기만 하는 일반 사용자라 비록 구체적인 내부 작동 원리를 이해하긴 어렵다고 해도 혹은 필요 없다 해도, 실제적으로 Transformer가 하는 일이 무엇인지 아는 것은 AI 시대를 살아가는 데 있어 좋은 상식이 될 것 같습니다.
Transformer는 OpenAI의 ChatGPT, Google의 Gemini, Anthropic의 Claude 등 오늘날 최고 수준의 능력을 보여주는 LLM들의 근간이 되는 기술입니다. 물론 각 회사는 표준(?) Transformer에 자신만의 Know-how를 적용하는 등 많은 추가/수정을 가하고 있어서 사용자 입장에서 경험하는 모델별 성능/능력에는 많은 차이가 존재합니다. (회사별 또는 LLM 모델별 성능/기능 차이가 나는 것은 모델의 알고리즘도 영향을 줄 수 있지만 사전 학습 방법이나 학습에 사용된 데이터의 품질로도 많은 차이가 생길 수 있습니다.) 참고로, Transformer는 2017년 8명의 Google 소속의 연구원들이 발표한 논문을 통해 세상에 알려졌습니다. 이것의 가장 큰 특징이자 혁신 중 하나는, 기존의 자연어처리(NLP: Natural Language Processing) 모델들과는 달리 언어 데이터 처리/학습에 있어 '병렬성'을 극대화를 시켰다는 것입니다.
잠깐 여기서 말하는 병렬성(Parallelism)에 대해서 이야기하면, Transformer 이전 시기에 NLP에 사용된 신경망 모델들(RNN 기반의 변형 모델들)은 입력되는 문장 속 단어들의 순서에 따라 한 번에 한 단어씩 입력/처리를(직렬 연산) 해야만 했습니다. 이로 인해 비록 행렬 연산으로 구성된 신경망 그 자체는 병렬적인 연산 구조를 가지지만, 언어 모델 자체는 직렬적이었기 때문에 사전 학습 혹은 이후 서비스(Inference) 단계에서 처리/응답 속도를 높이기 위해서는 더 빠르게 계산할 수 있는 컴퓨팅 인프라를 필요로 했습니다. 하지만 문제는, 기술 발달과 함께 컴퓨팅 처리 속도는 꾸준히 빨라지고는 있지만, 원하는 대로 처리 속도를 높일 수는 없었습니다. 심지어는 많은 돈을 투자할 수 있는 여력이 있다고 해도요.
반면에, Transformer는 입력된 문장 속 단어 전체를 동시에 학습(병렬 연산)할 수 있는 방식으로 되어 있습니다. (그 외에도 기존 RNN 기반 모델 대비 장점이 더 있지만) 이로 인해, 언어 모델의 능력/성능을 높이기 위해서는 더 빠른 컴퓨터보다는 한 번에 처리/계산할 수 있는 처리용량 즉 컴퓨팅 인프라의 규모를 늘리는 것이 의미를 갖기 시작했고, 충분한 돈만 있다면 늘어난 컴퓨팅 인프라의 규모를 활용하여 사전 학습 데이터의 양과 언어 모델의 크기(파라미터의 개수)를 크게 늘리는 것을 시도해 볼 수 있게 되었습니다. 참고로, 신경망의 '지능'은 파라미터의 개수가 많을수록(모델의 크기가 커질수록) 대체로 높아지는 것으로 알려져 있습니다.
이에 MS에서 투자 유치에 성공한 OpenAI는 GPT 시리즈 개발 시, 정말 무식하다고 할 수 있을 정도로 학습 데이터의 양과 이를 수용할 신경망의 규모/크기(파라미터의 수)를 폭발적으로 늘렸습니다. (사실 MS의 투자라는 것은 현찰 투자가 아닌 MS의 클라우드 인프라 사용 권한이 대부분입니다.) 그리고 그런 시도를 통해 GPT-3에 이르러서는 정말 깜짝 놀랄 만한 성능을 보여주기 시작했습니다.
이렇게 언어 모델의 크기가 AI의 지능에 큰 영향을 준다는 점은 결국 초대형 언어 모델(LLM, Large Language Model)의 탄생과 이를 뒷받침할 병렬 처리의 핵심 요소인 GPU 확보를 둘러싼 글로벌 경쟁을 일으켰습니다.
CPU vs GPU 그리고 HBM.... 모든 것은 병렬을 위한 것!
CPU(Central Processing Unit)는 컴퓨터 시스템에서 주어진 로직을 따라 복잡한 연산을 수행하고, 시스템 전반을 운영하는 역할을 합니다. 반면에 최근에 유행어가 되어 버린 GPU(Graphic Processing Unit)는 주로 3D 컴퓨터 게임을 위해 CPU의 보조 장조로 처음 만들어진 디바이스입니다. 3D 게임이 GPU라는 별도의 연산 장치를 필요로 했던 것은, 거의 실시간으로 사용자의 입력에 반응하며 화면 속 수많은 물체의 움직임을 표현하기 위해서는 고속으로 엄청나게 '많은' 수학 연산을 할 수 있는 장치를 필요로 했기 때문입니다.
물론 이를 성능 좋은 CPU로도 할 수 있으나, 가격이 워낙 비쌌기 때문에 빠르면서도 많은 양의 연산을 필요로 하는 고해상도의 3D 계산을 하는데 CPU를 늘리는 데는 한계(낮은 가성비 등)가 있었습니다. 반면, 개별 연산 처리 장치(Core) 단위로 볼 때 GPU는 CPU보다 연산 성능이 훨씬 떨어지고 복잡한 로직/연산은 어렵지만 상대적으로 낮은 가격(?)에 단순한 연산을 효율적으로 처리할 수 있는 "엄청 많은" 수의 Core를 탑재할 수 있습니다. (높은 가성비) 참고로 2022년 출시된 NVIDIA의 H100 GPU 1개는 약 2만 개의 Core를 탑재하고 있습니다. 그런데, 2000년대에 들어와서 신경망 관련 계산에 GPU를 사용하는 방법이 알려지면서, AI의 성능을 높이는데 결정적인 요소로 역할을 하기 시작했습니다.
그렇다면, 이 GPU를 통한 병렬 연산 능력은 어떻게 발휘가 될까요? 3D 게임/그래픽 연산과 신경망 연산은 모두 다 엄청나게 크고 많은 양의 행렬 연산을 필요로 한다는 공통점이 있습니다. 그런데 이 행렬 연산이라는 것은 근본적으로 '병렬'적이기 때문에 GPU의 양을 늘리면 연산 속도를 계속 높일 수 있습니다.
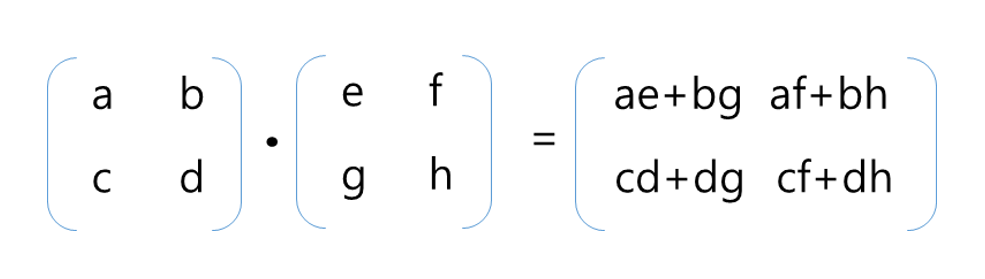
2차원 두 행렬의 곱하기 연산
위의 2차원인 두 행렬의 곱하기 연산 예시를 보면 "ae+bg", "af+bn" "cd+dg" "cf+dh" 각각의 연산은 독립적이기 때문에 병렬적 계산 구조를 가지고 있습니다. 즉, 1개의 Core를 가진 CPU는 4번의 연산을 '순차적'으로 해야 하지만, 4개의 연산 Core를 가진 GPU로 계산하면 각 Core가 동시에 1번씩 계산하면 되기 때문에, 단순하게 보면 4배의 연산 속도 차이를 만들 수 있습니다. 그런데 만약 행렬의 차원이 수천, 혹은 수만이고 이를 수백억, 수천억 번 연산해야 한다면 어떨까요? 병렬 처리 능력은 엄청난 차이를 만들 것입니다.
또한, 이런 병렬 연산을 제대로 하려면 이러한 연산(중간) 결과를 저장할 메모리를 필요로 합니다. 그런데 이 메모리 역시 병렬 처리의 효과를 극대화하기 위해 HBM(High Bandwidth Memory, 고대역폭 메모리) 능력이 절대적으로 중요한 역할을 합니다. 여기서 고대역폭이라는 것은 말 그대로 많은 데이터를 수많은 GPU Core와 동시에 주고받을 수 있게 하는 것으로, 대규모 행렬의 병렬 연산을 지원하기 위해 필요한 요소입니다.
그래서 정리를 하면, 기존에 CPU+일반 메모리가 1차선 고속도로를 1대의 페라리로 왕복하며 사람/물건을 운송하는 것이라면, GPU+HBM 메모리는 100차선 고속도로 위를 100대의 소나타가 왕복하는 거와 비슷한 것이 됩니다.
물론, 많은 업체와 연구소들에서 작은 크기의 LLM으로 효과적인 성능을 내는 모델을 연구/개발하고 있고, 금융/의료 등과 같은 특정 분야로 제한을 한 작은 규모의 LLM이 범용의 최첨단 상용 LLM과 비슷한(결코 앞서지는 못하고) 능력을 보인다는 발표들이 종종 볼 수는 있지만, 아직까지는 모델의 크기는 성능(지능)에 결정적인 역할을 하는 것으로 받아들여지고 있습니다. 물론 일반적으로 학습 데이터의 양에 비해 모델의 크기(파라미터의 개수)가 너무 크면 과적합(AI가 최적의 답을 찾는 것이 아니라 학습 데이터만을 그대로 따라 하는 것) 문제가 있지만 아직까지도 LLM 모델의 파라미터 개수를 비공개로 하면서 규모를 계속 늘리는 경쟁을 하는 것으로 볼 때 아직까지는 그 단계를 걱정할 때는 아닌 듯합니다.
한편, 이렇게 커져만 가는 AI 시스템으로 인해 AI를 운영하는 데이터센터는 몇 가지 어려움을 겪고 있는데, 그중 하나는 GPU의 확보입니다. 현재 AI에 최적화된 GPU를 만들 수 있는 업체는 NVIDIA가 거의 유일한 상태입니다. 이는 강력한 HW 성능뿐 아니라 AI 알고리즘별로 필요로 하는 연산을 최적으로 할 수 있도록 GPU의 계산 로직을 직접 커스터마이즈(병렬 처리의 극대화를 위해) 할 수 있도록 하는 CUDA(Computer Unified Device Architecture)라는 독자 기술을 제공하고 있기 때문입니다. 2007년에 최초로 공개된 CUDA는 오늘날 GPU를 활용하는 대부분의 SW 및 프로그래머들이 표준처럼 사용하고 있어 NVIDIA가 아닌 다른 업체 제품으로의 교체를 어렵게 하고 있습니다. 그런데 AI 데이터센터가 AI의 사전 학습 및 원활한 서비스(Inference)를 지원하기 위해서는, 예를 들면 1개당 가격이 웬만한 중대형 자동찻값 수준인 NVIDIA의 H100 GPU 같은 것을 수천~수십만 개 단위로 필요로 합니다.
이로 인해 전 세계적인 AI 열풍 속에서 너도나도 GPU를 찾기 시작했고, 이는 결국 글로벌한 GPU 공급 부족 사태로 이어졌습니다. 그리고 이는 지금도 진행형입니다. 물론 이런 NVIDIA의 독점으로 인한 위험과 비용을 줄이기 위해서 주요 IT 업체들은 자체적으로 GPU를 개발하고 있으나, 앞서 언급된 이유 등으로 아직은 부족 상황이 해소되지 않고 있습니다. 이 이슈는 아이러니하게도 이 모든 AI 열풍의 시작점이었던 OpenAI도 마찬가지로 겪고 있는데, CTO(Chief Technology Officer)였던 미라 무라티(Mira Murati)는 어느 인터뷰에서 자신의 업무에서 GPU 확보가 굉장히 중요하다고 했을 정도입니다. 이는 결국 아래 차트에서 보이는 것처럼 NVIDIA 주가 폭등으로 이어졌습니다.
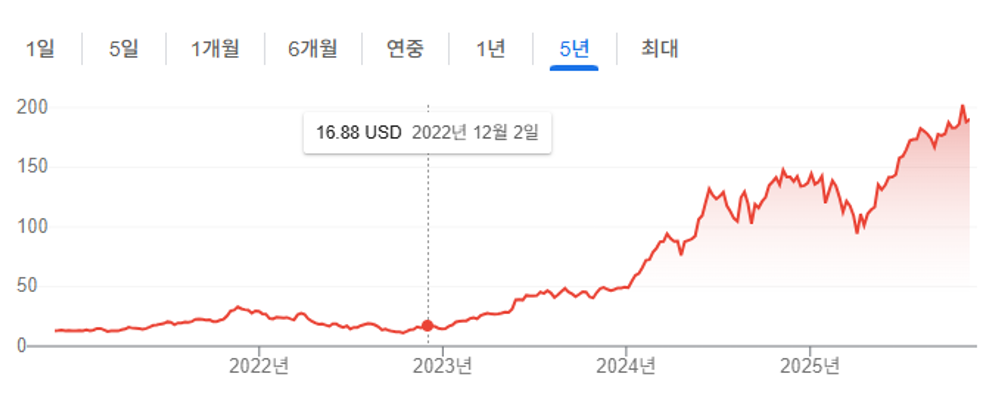 대표적 GPU 업체인 NVIDIA의 주가 변화
대표적 GPU 업체인 NVIDIA의 주가 변화
2022년 부터 2025년까지의 NVIDIA 주가 폭등하는 모양의 차트
게다가 문제는 GPU 확보에서 끝나지 않는다는 점입니다. 즉 GPU의 확보도 중요하지만, 이를 움직이게 하기 위해서는 엄청난 양의 전력을 필요로 합니다. 또한, GPU를 움직이는 데도 전력이 필요하지만, 그 GPU가 내뿜는 열기를 냉각시키는 데에도 엄청난 전기를 필요로 합니다. 그래서 Google의 경우 자신들의 데이터센터를 위한 전용 핵발전소 건립을 고민 중이라는 뉴스가 나오기도 했습니다.
Next Token Prediction
그렇다면 원래의 질문으로 돌아와, Transformer가 그 방대한 데이터에 대해 학습하고 입력된 데이터에 대해 엄청난 연산을 해서 결국 하는 일은 무엇일까요?
Transformer는 바로... 주어진(사용자가 입력한) 문장의 끝에 바로 이어서 나올 가능성(확률)이 가장 높은 단어 혹은 토큰(Token)을 예측(Next token prediction)합니다. 즉, 입력된 문장에 대해 Transformer 내에서 Attention 등의 복잡한 연산을 거쳐 최종 단계에서는 해당 LLM이 구사하는 모든 단어에 대해(입력 문장 다음에 올) 확률을 계산합니다. 그리고 그중에서 가장 확률이 높은 단어를 선택해서 사용자에게 출력하고, 입력된 문장에 출력된 단어를 결합하여 다시 입력하는 절차를 문장 종료 마크가 출력될 때까지 이것을 반복합니다.
토큰(Token)이란...
최소한의 의미를 갖는, 단어보다 더 작은 단위를 지칭하는 용어로 이를 통해서 AI가 학습할 때 그리고 사용자의 질문(Prompt)을 이해할 때 단어/문장의 의미를 더 잘 파악할 수 있게 합니다. 대체로 토큰은 기본 단어와 같지만, 예들 들어 "unpredictable(예측할 수 없는)" 같은 단어는, Token화하는 알고리즘/방식에 따라 다소 차이가 있을 수 있지만, "un" + "predict" + "able"와 같이 3개의 Token으로 분해가 될 수 있습니다. 이런 방식을 통해 AI는 접두사, 접미사 등의 어형변화(Inflection)를 같이 학습할 수 있게 됩니다. 참고로, 일반 단어를 토큰으로 변환하는 작업을 Tokenization이라고 합니다.
예를 들면, 최초에 Transformer에 주어진(입력되는) 문장이 "I love"라 한다면, Transformer는 자신이 학습했던(Pre-Trained) 엄청난 양의 문장 데이터(Corpus)를 기반으로 "I love" 뒤에 나올 가능성이 가장 높은 단어가 무엇인지를 찾아내서(계산해서) 출력합니다. 좀 더 구체적으로는, 앞에서 설명한 바와 같이 Transformer가 구사할 수 있는 전체 단어 각각별로 확률을 계산해서 가장 확률이 높은 단어를 찾아 냅니다. 만약에 10만 개의 단어를 구사하는 Transformer라고 하면 10만 개 단어 각각에 대해 확률을 계산하게 되는 겁니다. 그래서 "I love"의 경우라면, 그 뒤에 올 가능성이 가장 높은 단어는 아마도 "you"일 겁니다. 물론 "him", "her", "them" 같은 단어가 온다고 해도 틀린 것은 아니지만 현실에서 가능성(확률)이 가장 높은 것은 "you" 일 것입니다. AI가 "you"를 출력하고 난 그 다음엔 "I love"에 "you"를 결합한 "I love you"를 입력 문장으로 해서 다시 문장 끝에 올 확률이 높은 단어를 예측/계산하고 출력을 합니다. 예를 들면 "so"가 될 수 있을 겁니다. 이런 식으로 계속 문장을 생성해 나가는 것입니다.
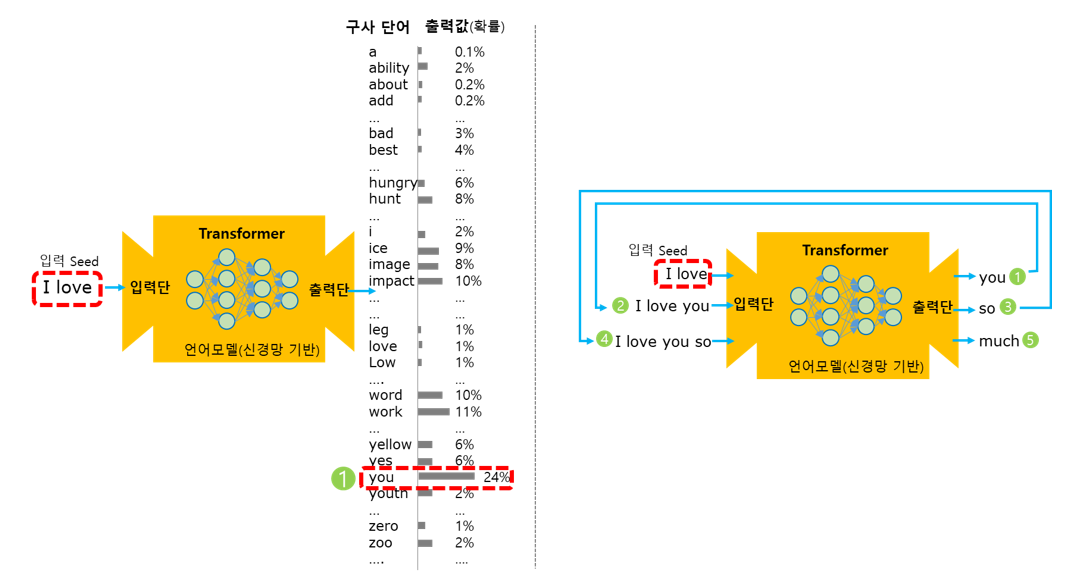
- 입력seed "I love" → 입력단 → Transformer(언어모델 - 신경망기반) → 출력단 → 구사단어 "you" / 출력값(확률) - 24%
- 입력seed "I love" → 입력단 → Transformer(언어모델 - 신경망기반) → 출력단 → 구사단어 "you" → 입력seed "I love you" → 입력단 → Transformer(언어모델 - 신경망기반) → 출력단 → 구사단어 "so" → 입력seed "I love you so" → 입력단 → Transformer(언어모델 - 신경망기반) → 출력단 → 구사단어 "much"
참고로, 여기서 말하는 Next Token Prediction의 Prediction 즉 '예측'이라는 것은 엄밀히 말하면 확률은 아니나 신경망을 통해 출력되는 단어별 출력 데이터의 값을 Softmax라는 함수를 사용하여 0에서 1 사이의 값으로 Normalize(동시에 전체 단어들의 확률을 더하면 1(100%)이 됨)하여 보기 쉽게 변환하게 되면 마치 확률 같은 모습으로 보이기 때문에 확률이라는 표현을 사용합니다.
그래서, 순수하게 Transformer의 알고리즘만 본다면, AI는 한 번에 한 단어씩 답변(출력)을 하기 때문에 자신이 전체적으로 어떤 대답을 하게 될지 사전에 알지 못합니다. 관련해서 이런 약점(?)을 확인할 수 있는 질문(Prompt)이 있는데, AI는 별도의 보조적인 보완책이 없다면 다음 같은 사용자의 질문에 절대 정답을 답할 수 없습니다.
"지금, 이 질문에 대한 너의 대답은 몇 단어로 구성되지? (How many words are in your response to this prompt?)"
물론 위의 질문과 답변이 Pre-Train(사전 학습) 단계에서 학습한 데이터 중에 있었다면 정답을 맞출 수도 있겠지만 일반적으로는 어렵습니다.
Attention 메커니즘과 Next Token Prediction
Transformer내 가장 중요한 부분인 (Self) Attention 메커니즘은 2017년 발표된 "Attention is all you need"라는 논문을 통해서 처음으로 공개됐습니다. 이 Attention은, 그 이전에 등장한 Word2Vec이 개별 단어를 고정된 임베딩 벡터로 치환하는 것에 머물렀던 것에 비해, Transformer에 입력된 문장의 내용을 보고 각 단어 의미를 문맥에 맞게 동적으로 수정을 합니다. (단어 임베딩 벡터 수정)
"우리는 다리(Bridge)를 무사히 건너갔다"
"어제 산에 갔다가 다리(Leg)를 다쳤다"
위의 두 문장 속 “다리”는 비록 글자는 같지만, 의미는 서로 다르다는 것을 우리는 쉽게 알 수 있습니다. 그런데 우리는 그것을 어떻게 알았을까요? 그것은 문장 내 다른 단어들을 보고 알 수 있게 됩니다. 특히, 그중에서도 서술어인 “건너갔다”와 “다쳤다”라는 단어를 통해 각 문장 속 "다리"의 의미를 다르게 그리고 정확하게 이해할 수 있게 됩니다. 이와 같이, 같은 단어라 해도 문맥에 따라 그 의미를 다르게 해석해야 하는데, 이때 Attention 메커니즘은 같은 단어라 해도 문맥에 따라 동적으로 새로운 임베딩 값으로 조정을 해 줍니다.
즉, Transformer 내 Attention 메커니즘은…
- 각 문장 속에 있는 “다리”가 해당 문장 속의 어떤 단어와 더 연관성이 있는지를 혹은 어떤 단어에 더 관심을 집중(Attention)해야 하는지를 계산합니다. (“다리”라는 단어를 기준으로 해당 문장 내 모든 단어와 순차적으로 연관성/유사도를 계산합니다, 그러면 위의 예시의 경우, ‘다리-건너갔다’, ‘다리-다쳤다’ 사이에는 다른 단어들간 대비해 더 높은 연관성/유사도가 있음을 계산으로 알아내게 됩니다.)
- 위에서 얻어진 값들은 문맥의 의미를 담는 ‘가중치’가 되며, 이 단어별 가중치를 본래의 문장 내 각 단어들의 임베딩 벡터값과 가중합을 하여 새로운 임베딩 값을 얻어냅니다.
이렇게 되면, Attention 메커니즘을 통과하기 전에는 위의 두 문장 속 “다리”는 같은 임베딩 값을 가지고 있었지만, Attention 처리를 하고 나면 첫 번째 문장 속 “다리”는 “건너갔다”라는 단어 임베딩 벡터 쪽으로 이동된 새로운 임베딩 값으로 변경이 되고, 두 번째 문장 속 “다리”는 “다쳤다”라는 단어의 임베딩 위치 쪽으로 이동된 새로운 값으로 변경이 됩니다. (그리고 위와 같은 계산을 “다리”뿐만 아니라 해당 문장 내 모든 단어별로 진행합니다.)
이제 문맥의 정보를 충분히 담도록 수정된 임베딩 벡터들은 이제 Next Token Prediction을 위한 입력값으로 사용이 되는데, 그 중에서도 문장 맨 마지막 단어의 임베딩 벡터는 그 단어 앞까지의 문장 내용이 응축된 정보를 가지게 됩니다. 그런 맨 마지막 단어를 기준으로 해당 LLM이 구사하는 모든 단어(Vocabulary)와 연관성/유사도를 계산하고 이렇게 얻어진 값 중에서 가장 큰 연관성/유사도를 가진 단어를 찾아 사용자에 출력하게 되면, 바로 그것이 Next Token Prediction이 됩니다.
물론 위의 설명은 Attention을 핵심 개념을 이해시키기 위해 단순화된 것으로 실제로는 훨씬 더 복잡하고 다단계의 계산을 거칩니다.
또한, 이미 많이 알려진 바와 같이 Transformer를 기반으로 하는 AI는 수학 계산, 그것도 아주 단순한 덧셈조차도 제대로 못 하는 것을 볼 수 있는데 이 역시도 AI는 실제로 주어진 문제에 대해 연산하는 것이 아니라 기존에 학습했던 자료를 바탕으로 가장 유사한 단어를 출력하는 것이기 때문입니다. 즉, "2 + 2 =" 라는 질문(입력값)에 대해 Transformer는 덧셈 연산을 하는 것이 아니라 역설적이게도 그 보다 훨씬 복잡하고 다단계의 다른 연산(Next Token Prediction)을 하느라 틀린 답을 내놓을 수 있다는 것입니다. (물론 2 + 2 와 같이 많이 언급되는 사례는 학습 데이터에 포함되어 정확한 답을 할 가능성이 높지만, "243 + 2,111 + 6,221 + 53 + 1,412 + 91 ="과 같이 연산 자체는 아주 기초적인 수준이지만 해당 연산 사례는 보지 못했을 가능성이 높기 때문에 정답을 맞추기 어려울 것입니다.)
참고로, 현시점에서 OpenAI를 비롯해 최선두에 있는 상용 LLM들은, 위와 같은 수학 연산의 경우 Transformer에만 의지하지 않고 다른 보완적인 기능/기법/알고리즘을 병행 사용하고 있어 올바른 답을 합니다. (하지만 초기에는 제대로 답하지 못했기 때문에 AI 사용법 교육 시 (단순한) 계산도 믿지 말라는 가이드가 퍼졌습니다.)
Context Window
앞서 설명해 드린 바와 같은 Next Token Prediction을 반복하다 보면 Transformer에 입력되는 문장의 길이가 무한정 길어지게 될 수 있을 겁니다. 당연히 이렇게 입력 문장의 길이가 너무 길어지면 LLM 시스템의 메모리나 처리 속도 등에 문제를 만들게 됩니다. 그래서 모든 LLM은 입력 문장의 길이에 제한(Context Window)을 둡니다. 예를 들면 오픈 초기의 ChatGPT(GPT-4)는 약 8,000개의(영어 기준) 토큰이 한계였습니다. 그럼 만약 제한된 입력 단어/토큰 수의 한계를 넘는 입력이 들어오면 어떻게 될까요? AI는 Context Window 크기를 벗어나는 앞부분(대화의 초기 부분)부터 입력하지 않고 잘라 버립니다. 그렇게 되면 AI는 대화 앞에 대한 '기억'이 없기 때문에 때로는 엉뚱한 대답을 하게 됩니다. (마치 사람처럼 시간이 흐르면 오래된 기억은 조금씩 사라지고 희미해지는 것과 같아서 흥미롭습니다.) 그래서 이러한 이유로 하나의 대화 세션을 길게 가져가는 것은 피해야 한다고 권고되어 왔습니다.
이에 업체들은 꾸준히 이를 개선하기 위한 연구와 투자를 이어온 결과, 최근 GPT-4 모델의 경우 Context Window가 12만 개 넘었고, Google의 Gemini 1.5 Pro 모델의 경우 이미 지난 2024년 Google I/O 2024에서 발표된 것에 따르면 기존 1백만 개에서 2백만 개로 늘어난다고 합니다. 이 정도 크기라면 일상적인 상황에서는 문장 길이에 신경 쓰지 않아도 될 것 같습니다. 사실 백만 단위의 Context Window는 Text 기반의 문장뿐 아니라 훨씬 데이터의 양이 많은 이미지나 동영상에 대한 분석도 가능하게 합니다. 예를 들면, Google의 Gemini 홍보 영상을 보면 1시간 분량의 영상을 프롬프트 입력창에 입력한 후 역시 프롬프트를 활용해 해당 영상 속에서 특정 장면을 찾아내는 것이 나옵니다. (참고로, Text를 Token이라는 작은 조각으로 분해했듯이 동영상도 Patch라고 하는 작은 조각으로 분해하여 학습하고 입력 데이터를 이해하기도 합니다.)
그밖에 Context Window가 커지면 혜택을 볼 수 있는 것에는, 현재 AI가 가장 많이 사용되고 있는 프로그래밍 분야가 있습니다. 사실 컴퓨터 프로그램도 일종의 언어이기 때문에 LLM 기반 AI가 능력을 발휘하는 영역입니다. 그런데 Context Window가 작을 때는 AI가 복잡한 로직으로 연결된 긴 코드를 한 번의 답으로 만들어 낼 수가 없습니다. 즉 하나의 로직으로 연결되는 코드를 AI는 쪼개서 답을 만들어 내질 못하기 때문입니다. 그래서 현재는 크고 복잡한 로직 개발에 AI 도움을 받고자 한다면, 사용자가(프로그래머가) 전체 로직을 생각하고 그 로직을 작은 조각으로 분해한 후 각각의 작은 조각별로 원하는 바를 프롬프트를 통해 답을 받은 후 사용자가 전체 조각을 직접 조합을 해야 했습니다. 아니면 포기하고 단순한 로직을(길이가 짧은 로직) 만드는 것에만 적용하던가요. 하지만, 늘어난 Context Window는 오류 없이 더 긴 프로그램을 만들 수 있게 합니다. 활용 범위가 확 늘어난다고 볼 수 있습니다.
참고로, 입력 데이터의 길이가 늘어난 LLM들의 성능을 평가하는 방법이 있는데 이를 보통 "The Needle in a Haystack" 테스트라고 불립니다. 우리말로 번역하면 "모래 속에서 바늘 찾기" 정도가 되는데요. 이 테스트는 엄청나게 긴 Text 데이터 속에서 AI가 특정 문장/단어를 얼마나 정확하게 찾아내는지/기억하는지 테스트하는 것입니다. 예를 들면 소설 "노인과 바다" 본문 중간에 "My phone number is xxxxxxxxx" 같이 원래 소설에 없던 Text를 끼워 놓고 프롬프트를 통해서 전체 소설의 본문을 입력한 후 "내 전화번호가 뭐였지?"라고 물어서 정확하게 답변하는지 확인하는 것입니다.
관련해서 아래의 Chart는 128K(128,000)개의 토큰 Context Window를 가진 GPT-4와 200K(200,000)개 토큰 Context Window를 지원하는 Claude 2.1에 대해 Needle In Haystack 테스트를 진행한 결과입니다. 각 Chart의 가로축은 Context(예를 들면 “노인과 바다” Text)의 길이를 나타내며 오른쪽으로 갈수록 긴 Context를 의미하고, 세로축은 "전화번호"를 그 Context의 어디에 배치했는가를 보여줍니다. 위로 갈수록 Context의 앞부분을 의미하고 아래로 갈수록 Context의 뒷부분을 의미합니다. 녹색은 정상적으로 "전화번호"를 제대로 답변한 것을 의미하고 붉은색은 제대로 답을 못한 것을 나타냅니다. 그래서 GPT-4 128K 모델의 경우 Context 길이가 짧을 때는 "전화번호"를 Context 내 어디에 배치하든 정확하게 답변을 합니다. 그러나 Context 크기가 늘어나면 주로 Context의 앞부분에 끼워 놓은 "전화번호"를 제대로 답변 못하는 것으로 나옵니다. 반면에 Claude 2.1 200K 모델의 경우 GPT-4현시점에서 OpenAI보다는 떨어지는 정확성을 보여주고 있습니다.
*단, 각 모델은 지속적으로 성능 업그레이드/튜닝을 하고 있어 현재 시점에서는 결과가 다르게 나올 수 있으니 Context Window의 개념 파악에 의미를 두시면 좋을 것 같습니다.
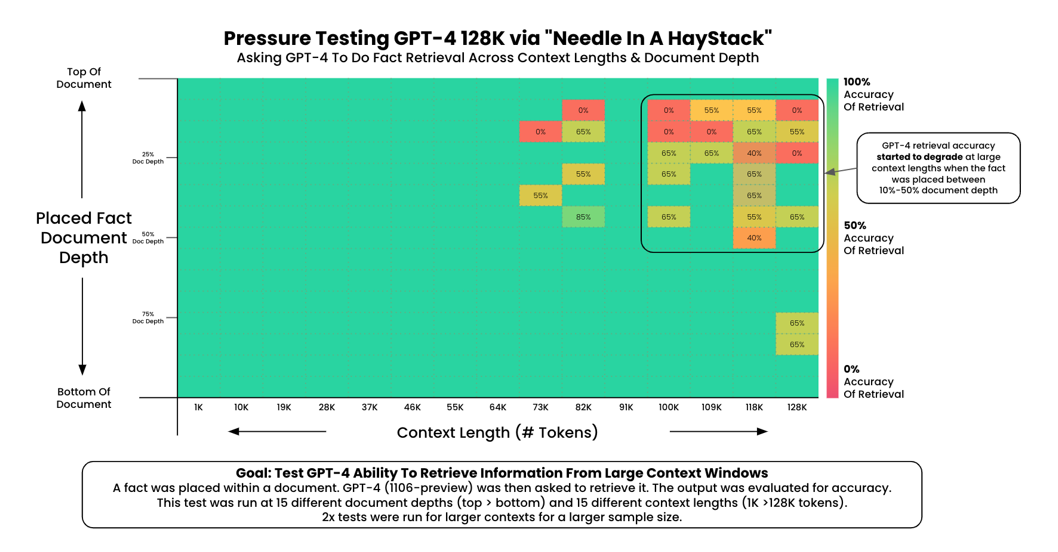
GPT-4-128K 그래프
그래프는 모델이 매우 긴 문서 안에서 특정 정보를 얼마나 잘 찾아내는지를 보여준다. 세로축은 정보 찾기 정확도(%), 가로축은 문서 길이(토큰 수)를 나타낸다. 문서가 길어질수록, 그리고 정보가 문서의 다양한 위치에 있을 때 정확도가 어떻게 변하는지를 색상 혹은 막대 형태로 시각화한다. 전체적으로 문서 길이가 극도로 길어질 경우 정확도가 떨어지는 경향이 보인다.
 이미지 출처: https://github.com/gkamradt/LLMTest_NeedleInAHaystack?tab=readme-ov-file
이미지 출처: https://github.com/gkamradt/LLMTest_NeedleInAHaystack?tab=readme-ov-file
Claude 2.1 그래프
그래프는 모델이 긴 문서 안에서 특정 정보를 찾아내는 성능을 문서 길이(토큰 수)별로 보여준다. 세로축은 정보 검색 정확도(%), 가로축은 문서 길이를 나타내며, 색상은 높은 정확도(녹색)에서 낮은 정확도(빨간색)까지의 변화를 표현한다. 문서가 길어질수록 전반적인 정확도가 감소하고, 특히 문서 중간이나 끝부분에 있는 정보를 찾는 데 더 어려움을 겪는 패턴이 나타난다.
이 Context Window 확장은 단순히 대화 길이를 길게 해주는 것 이상으로, 현재 AI의 주요한 발전 방향이 될 수 있는 개인화된 AI 구현의 시작점이 됩니다. 관련해서 이미 OpenAI에서는 'Memory'라는 기능을 제공하고 있는데, 이는 AI가 사용자와의 대화 도중에 언급되는 개인 관련 정보에 대해 'Memory'에 저장하고 추후 AI가 답변할 때 이를 활용/기준으로 사용하여 답변하는 방식으로 동작합니다. 예를 들면 사용자의 가족 관계나 거주하는 지역/사용 언어, 좋아하는 음악 장르, 답변 방식 등에 대한 정보입니다. 이때 사용하는 방법은, 공식적으로 확인되진 않아 추정이긴 하나, 'Memory'에 저장된 내용을 사용자가 입력하는 프롬프트에 추가하여 LLM에 입력하는 방식인 것으로 보입니다. 하지만, 진정한 의미의 개인화된 AI는 단순히 사용자의 선호 혹은 개인정보에 대한 것 뿐 아니라(주요) 대화 내용/이력도 함께 기억할 수 있어야 할 것입니다.
Temperature(K)
앞에서 Next Token Prediction에 대해서 설명을 했는데요. 앞에 이론적 설명과 달리 우리가 실제로 경험하는 AI들은 사용자로부터 똑같은 질문을 반복적으로 받아도 똑같은 대답을 하는 경우가 거의 없습니다. (매번 새로운 대화 세션에서 첫 번째 질문을 같은 것으로 해도) 즉, 마치 사람의 반응처럼 매번 조금씩 다르게 답변하는 것을 경험하셨을 텐데요. 물론 대부분의 경우, 그 답변의 내용/취지는 대동소이하고 다만 그것을 표현하는 방식에서만 조금씩 차이가 납니다. 그럼 앞서 설명한 Next Token Prediction과 상충하는 거 아닌가 하실 수 있는데요. 엄밀히 설명하면 대부분의 AI들은 문장 끝에 나올 단어 중 "가장 확률이 높은 단어"를 선택하는 것은 아니고, 일정 수준의 높은 확률을 가진 Token 중 하나를 선택하는 것입니다. 이렇게 되면 출력되는 Token으로 만들어진 문장이 매번 조금씩 달라지게 됩니다. 물론 전체 맥락은 일정하게 유지되면서요. 이와 관련 되서 LLM의 내부 설정값(Hyperparameter) 중 하나로 사용되는 개념이 있는데 바로 '온도(K)'라는 것입니다. '온도'는 Transformer 아키텍처의 마지막 단계에서 적용되는 개념으로, 입력 문장 뒤에 나올 단어(Token)을 찾기 위해 해당 LLM이 알고 있는 모든 단어에 대해 확률을 계산하는 로직인 Softmax 함수에 변형을 가하여 출력 후보 단어들의 확률 차이를 변화시킵니다.
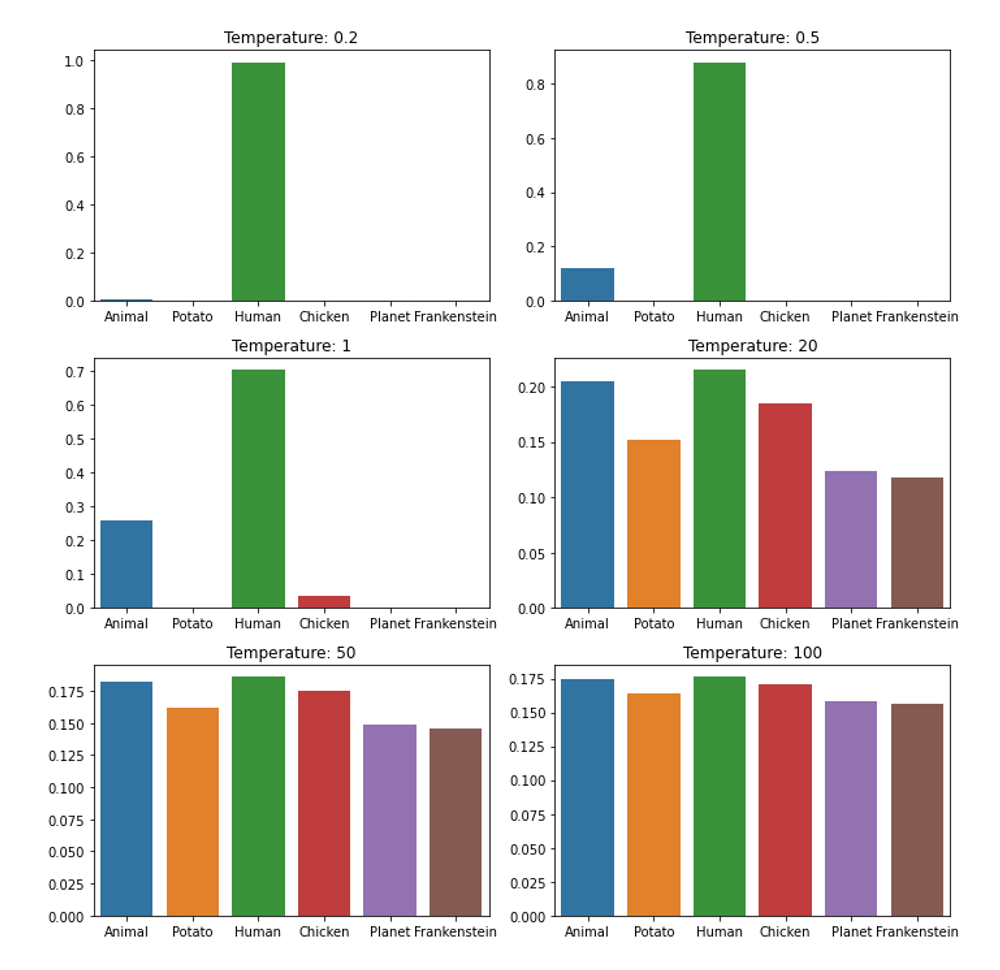 이미지 출처: https://shivammehta25.github.io/posts/temperature-in-language-models-open-ai-whisper-probabilistic-machine-learning/
이미지 출처: https://shivammehta25.github.io/posts/temperature-in-language-models-open-ai-whisper-probabilistic-machine-learning/
여러 다른 온도(temperature) 값에 따른 소프트맥스 확률 분포를 막대그래프로 보여주는 이미지. 각 서브플롯은 서로 다른 온도(예: 0.2, 0.5, 1.0, 큰 값 등)에 대응하며, 세로축은 확률 비율, 가로축은 가능한 토큰(예: ‘Animal’, ‘Potato’, ‘Human’, ‘Chicken’, ‘Planet_transformation’ 등)이다. 온도가 낮을 때(예: 0.2)는 분포가 매우 뾰족해서 특정 토큰(‘Human’)에 확률이 거의 몰려 있고, 온도가 높아질수록 분포가 더 균등해지고 다른 토큰들도 유의미한 확률을 갖게 된다
그래서 위 도표에서처럼 온도를 높이면 낮은 확률의 단어에게도 선택될 기회가 돌아가게 되고 온도를 낮추면 Token 간 확률 차이가 크게 벌어져서 가장 확률이 높은 단어가 선택되게 됩니다. 그래서 시를 쓰고 싶다든가 새로운 아이디어를 얻고자 할 때는 온도를 높이고 정확한/일관된 답을 원할 땐 온도를 낮추게 됩니다. 즉, 온도를 낮추면 답변의 일관성이 높아져 '헛소리'를 할 가능성이 낮아지고, 반면에 온도를 너무 높이면 창의적인 것을 넘어서 AI는 알 수 없는 말을 출력하게 되거나 혹은 그 유명한 환각(Hallucination)이 발생합니다.
현재 대부분의 Transformer 기반 AI Chatbot들은 온라인 프롬프트를 통해서는 온도를 조절할 수 없게 되어 있지만 '온도'를 직접 설정/변경하고 이를 경험해 볼 수 있는 방법이 있는데, OpenAI의 경우, 홈페이지를 통해 개발자들을 위한 테스트 공간인 "Playground"에서 온도 변경을 경험할 수 있습니다. 그 외에는 MS의 Bing Chat의 경우 "대화 스타일 선택" 메뉴를 통해서 제공되는 옵션 3가지("보다 창의적인", "보다 균형 있는", "보다 정밀한")에 대한 선택을 통해서 '온도'를 변경할 수 있게 되어 있습니다.
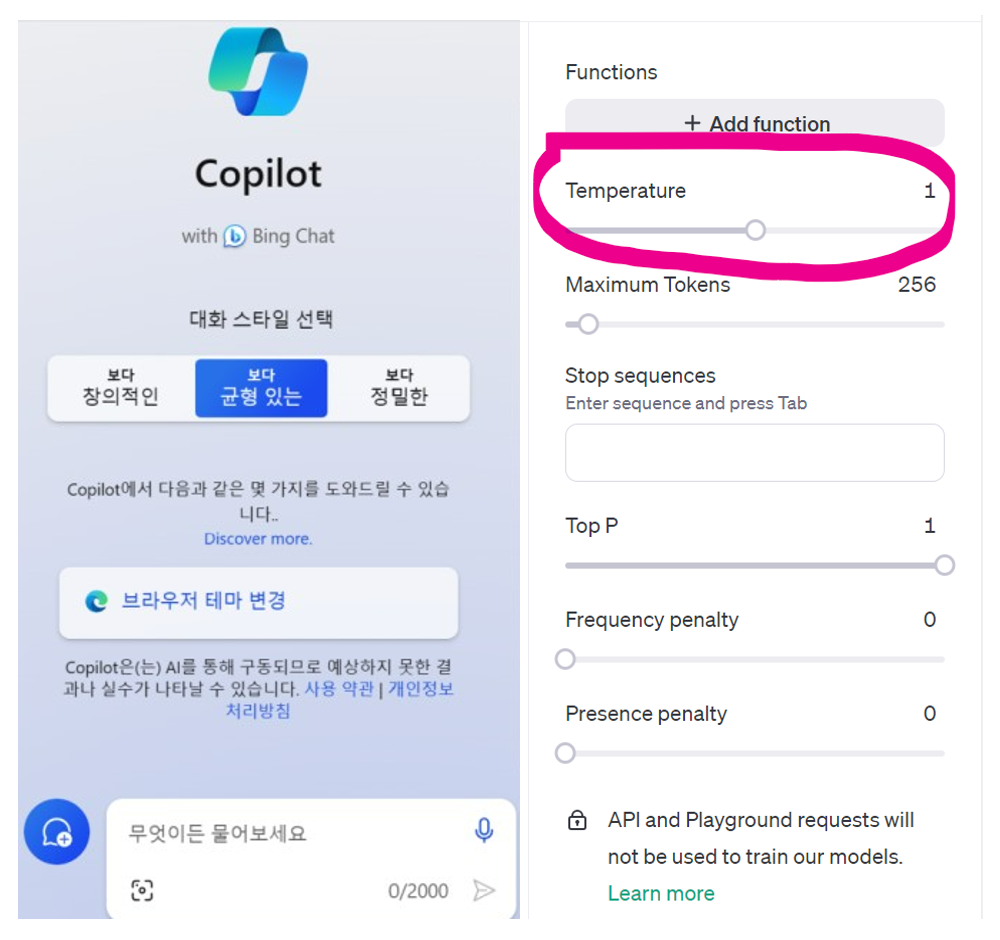 이미지 출처: MS Bing Chat Copilot(Mobile) / OpenAI ChatGPT Playground
이미지 출처: MS Bing Chat Copilot(Mobile) / OpenAI ChatGPT Playground
MS의 Bing Chat에서 대화 스타일 메뉴의 옵션3가지("보다 창의적인, 보다 균형있는, 보다 정밀한")에 대한 선택을 통해 경험할 수 있는온도 변경 화면(좌),
OpenAI의 Playground에서 경험해볼 수 있는 온도 변경 화면(우),
참고로, Softmax 처리 이후 단계에서 출력 단어/Token을 선택하는 방법에는, 위에서 언급된 가장 확률이 높은 단어를 선택하는 Greedy Search 이외에, 전체 출력 문장의 최적화(최대 확률)를 추구하는 Beam Search, 그리고 위에 언급된 '온도'와 같은 다양한 Sampling 방법들이 있습니다. 좀 더 자세한 사항이 궁금하신 분들은 위의 키워드로 검색해 보시면 다양한 자료들을 찾으실 수 있을 겁니다.
또한, 위에 설명된 출력 단어의 선정을 위한 Next Token Prediction을 넘어서, 현재 AI 분야에서 가장 선두에 있는 OpenAI는 이미 ChatGPT o1-preview부터, 사용자의 질문에 답변 시 여러 대안을 탐색하고 이 중에서 가장 적절한 최적의 답변을 분석/계산한 후에 답변하는 논리적 탐색 기능을 제공해 왔고 계속 발전하고 있습니다.
마치며….
이상 Gen AI 혁명의 근간이 된 Transformer의 핵심적인 동작 원리 및 특징들에 대해서 살펴보았습니다.
AI는 지금도 전 세계적으로 가장 많은 관심을 받고 있는 분야이며 비록 최근에 거품론이 떠오르고 있기는 하지만 여전히 우리 미래에 가장 많은 영향을 미칠 기술임에는 반론의 여지가 없습니다. 그렇기 때문에 비록 우리가 고성능/고품질의 독자적인 AI 모델을 개발하는 것은 사실 쉽지 않은 일이라 해도, 최소한 그것을 사용하는 입장에서라도 그 기본 동작 원리를 이해하고 있으면 이 기술을 좀 더 잘 사용할 수 있을 것으로 판단됩니다.
본 이티클이 AI 기술 이해에 도움이 되길 바랍니다.
FAQ
-
AI는 사람의 말을 어떻게 이해하나요?
단어 자체보다는 문맥, 의도, 의미를 종합적으로 분석하여 사용자의 의도를 파악하는 방식으로 이해합니다.
-
왜 대화 이해가 어려운가요?
인간의 언어는 모호하고 생략이 많으며, 상황에 따라 의미가 달라지기 때문에 단순 규칙으로 해석하기 어렵기 때문입니다.
-
기존 AI와 최신 AI의 차이는 무엇인가요?
기존 AI는 키워드 중심이었다면, 최신 AI는 문맥을 유지하고 대화 흐름을 이해하는 능력이 강화되었습니다.
-
문맥(Context)은 왜 중요한가요?
같은 문장이라도 이전 대화나 상황에 따라 의미가 달라지기 때문에 정확한 이해를 위해 필수입니다.
-
의도(Intent) 분석은 무엇인가요?
사용자가 실제로 무엇을 원하는지를 파악하는 과정으로, 정확한 응답 생성의 핵심 요소입니다.
-
앞으로 AI 대화 기술은 어떻게 발전하나요?
상황 인식과 감정 이해까지 포함한 보다 인간에 가까운 대화 능력으로 발전할 것으로 예상됩니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.

