

2019년 1월 24일부터 이틀간, 세계적 규모의 AI 컨퍼런스 중 하나인 ‘Deep Learning Summit 2019’가 미국 San Francisco에 위치한 Hyatt Regency 호텔에서 개최되었습니다. 필자는 출장을 통해 해당 컨퍼런스에 참석하여 최신 Deep Learning 트렌드에 대한 최신 동향 파악과 동시에 세계 각국의 엔지니어들과 네트워킹 할 수 있는 기회를 가졌습니다. Deep Learning Summit은 올해로 벌써 개최 5주년을 맞이하였으며, 올해는 10개의 Stage에서 100명 이상의 발표자들이 최신 연구 성과와 다양한 적용 사례에 대해 발표하였고, 전 세계에서 온 800명 이상의 엔지니어, 기획자, 경영진이 참석하여 컨퍼런스를 더욱 열정적으로 달아오르게 만들었습니다.
‘Deep Learning Summit 2019’의 각 Stage는 다양한 주제에 따라 동시다발적으로 각 홀에서 진행되었으며, 주최측에서 제공한 ‘sched’ 어플리케이션을 통해 본인이 관심 있는 세션을 스케쥴링 할 수 있었습니다. 1층의 Main Hall에서는 가장 큰 Stage인 “Deep Learning Stage” 가 진행되었고, 지하 1층의 각 소규모 홀에서는 튜토리얼, 환경, 윤리, 투자, 네트워킹, 토론 등 다양한 종류의 Stage들이 진행되었습니다. 참석자들은 각각의 관심사에 따라 자유롭게 홀을 이동하였고, 이동 중이나 각 Stage의 세션 참석 중에 서로 자유롭게 네트워킹을 하였습니다. 필자도 세션을 듣기 위해 자리나 중식 테이블에 함께 앉았던 다양한 해외 엔지니어들과 커뮤니케이션 할 수 있는 기회를 가질 수 있었는데, 처음 보는 사람과 나이, 성별, 직급에 상관없이 서로의 관심사와 기술적 백그라운드에 이야기를 주고 받는 걸 보면서 이들의 네트워킹에 대한 겸손하고 진지한 자세가 새삼 신선하게 느껴졌습니다.

필자는 주로 Deep Learning Stage에서 열린 세션에 참석했습니다. Deep Learning Stage는 주로 딥러닝의 기술적인 개선과 아이디어, 경험에 대한 발표로 이루어졌습니다. 다행히 각 주제와 적용 분야가 매우 다양하여, 집중력을 잃지 않고 발표를 들을 수 있었습니다. Deep Learning Stage에서 다뤄졌던 주제들을 간략하게 요약하자면 다음과 같습니다.
• 자율주행(Autonomous driving) 및 Robotics 성능 개선
• 강화학습(Reinforcement Learning)의 대두
• 지도학습 보완(Weak/Self/Simulated supervised learning)에 대한 방법들
• 의료(Healthcare)서비스로의 활용
지금부터 필자가 관심 있게 들었던 세션들을 중심으로 정리해 보겠습니다.
[RECENT ADVANNCES FROM OPENAI, lya Sutskever, Co-Founder & Research Director at OpenAI]
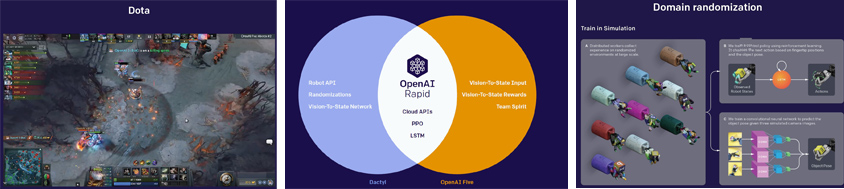
OpenAI에서는 지난 6개월 동안의 연구 성과에 대해 발표하였습니다. 발표자인 Sutskever는 AI Guru 중 한명인 Geoffrey Hinton 교수 아래서 수학한 제자 중 한명으로, OpenAI의 설립자이기도 합니다. OpenAI는 주로 Reinforcement learning에 대해 발표했는데, 최근 OpenAI의 연구과제의 핵심인 OpenAI Five와 Dactyl에 대해 설명했습니다.
OpenAI Five는 DOTA 게임의 Bot으로, Reinforcement learning을 통해 성장하여 최근 유수의 프로게이머들을 위협하는 중입니다. DOTA의 게임당 시간과 움직임 수가 적은 점, 그리고 많은 GPU/CPU파워에 힘입어 복잡한 경우에 수에 대해서도 학습을 시키는 데 성공했다고 합니다. Dactyl은 로봇 손을 통해 정육면체를 원하는 숫자가 보이는 데로 뒤집도록 훈련시키는 과정에서 훈련에 시뮬레이션을 이용하였습니다. 실제 물리적 환경을 학습시키려면 사실 모든 경우의 수를 완벽하게 통제해서 만들어 내는 게 불가능하지만(빛, 역학, 물리법칙의 영향 등), 시뮬레이션을 통해 환경을 만들어 내면 우리가 원하는 대로 모든 상황을 시뮬레이션 할 수 있습니다.
이렇게 상호 보완적인 Five와 Dactyl이 결합하면 인공 신경망이 매우 다양한 작업을 학습하고, 또 동작할 수 있는 인프라가 제공될 것이라고 Sutskever는 말했습니다. Reinforcement learning과 sim2real 기술이 앞으로 AI에 있어 빠르게 기존의 Supervised learning을 뛰어넘을 것이라는 느낌을 받았습니다.
[ Adversarial Machine Learning, Ian Goodfellow, Research Scientist at Google Brain ]
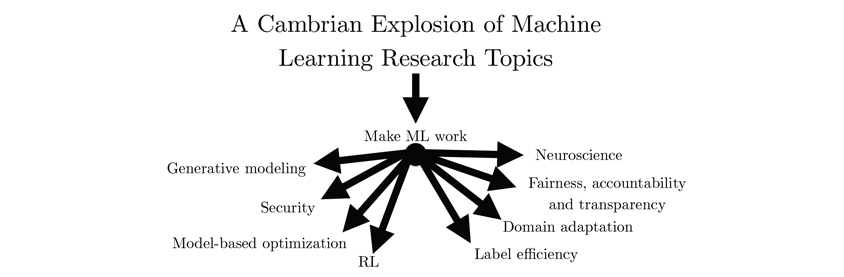
Google Brain은 GAN을 주제로 한 발표를 진행했습니다. GAN(Generative Adversarial Network)는 연예인들의 얼굴을 바탕으로 합성인지 구분할 수 없는 진짜 같은 얼굴을 생성해 내는 예제를 통해 접하신 경험이 많을 것입니다. 발표자인 Goodfellow는 이 GAN을 제안하고 논문으로 발표한 연구자이며, AI Guru 중 한명인 Andrew Ng 교수의 제자이기도 합니다. Goodfellow는 최근의 기계 학습 분야의 연구 주제의 다변화가 마치 캄브리아기 대폭발과 같다고 비유하였는데, GAN의 영향으로 인해 파생될 9가지 정도의 주제의 최신 경향에 대해 소개 주었습니다. GAN을 사용하게 되면 원본과 같은 정규분포를 따르는 가짜 정보들을 파생시킬 수 있는데, 이렇게 파생된 정보들을 바탕으로 각 도메인의 특성에 맞는 학습을 진행시키는 데 도움을 주게 됩니다. 특히 시뮬레이션 환경을 GAN과 연동하여, 지금까지 경험한 적이 없는 상황을 학습시키는 부분은 향후 Robotics 분야에서 많은 도움을 줄 것으로 생각됩니다.

제가 흥미롭게 느꼈던 것은 Neuroscience 분야의 연구였습니다. 예시로 보여준 고양이와 강아지 사진을 보면 순간적으로 판단해서는 어떤 사물인지 정확하게 판단이 되지 않습니다. 이렇게 GAN을 통해 생성된 이미지 중 컴퓨터의 Discriminator, 그리고 판단 시간이 제한된 인간이 모두 결정에 어려움에 영향을 주는 것들을 사용하여, 인간의 뇌가 작동하는 방식을 연구할 수 있다는 점이었습니다. 인공 신경망이 기본적으로 인간의 신경망을 본 따서 만든 만큼 인공 신경망에 대한 연구가 역으로 Neuroscience 분야에서의 많은 발견으로 이어질 수 있겠다는 생각이 들었습니다.
[Beyond Supervised Driving, Adrien Gaidon, Machine Learning Lead at Toyota Research Institute]
Toyota Research Institute에서는 자율주행을 개선을 위한 인공 신경망에 대해 발표했습니다. 자율주행을 위해서는 Computer vision에 기반한 Object detection, object recognition, instant segmentation등이 필요한데, 문제는 지금의 Supervised learning으로 학습된 인공 신경망이 성장하는 속도로 예측하면 완벽한 자율주행을 하는데 거의 100년 가까운 시간이 걸릴 것 이라는 점과, 테라바이트 단위의 수집된 정보를 모두 학습하는 게 불가능 할 것이라는 점이 중요한 문제로 대두되고 있습니다. Toyota는 이에 학습을 시뮬레이션 시키기 위한 아키텍쳐로 SPIGAN 네트워크를 제안하였습니다.
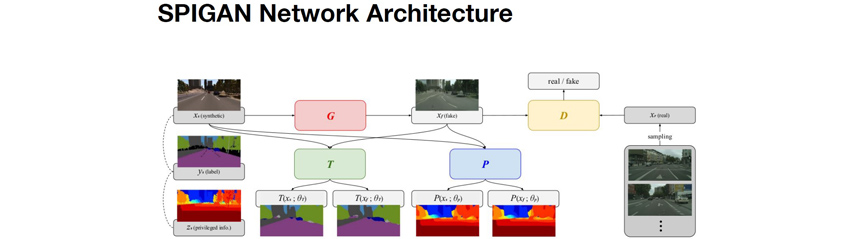
SPIGAN은 진짜 도로 주행 비디오와 유사한 Fake 비디오를 만들어내는 GAN 아키텍쳐, 그리고 시뮬레이션 생성 시 얻어진 z-buffer(깊이)를 바탕으로 자율주행 영상의 depth를 예측하는 P 네트워크, 그리고 segmentation을 예측하는 T 네트워크 등으로 구성됩니다. 즉, 네트워크가 학습됨에 따라 실제 영상 데이터에 대해 radar의 도움 없이도 영상에 등장한 물체의 거리를 파악할 수 있게 되는 것입니다.
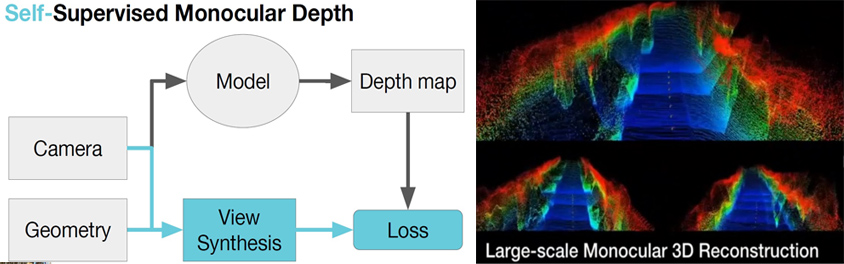
이 다이어그램은 SuperDepth에 대한 아키텍쳐로, SuperDepth는 Depth map 생성 시 추가적으로 제공된 guideline인 기하학적 정보를 바탕으로 모델을 스스로 수정하게 만든 아키텍처입니다. 모델을 테스트 한 결과 별도의 Label 처리 없이도 입력된 주행 영상의 depth 정보를 잘 반영하였고, 이를 바탕으로 궁극적으로는 꽤 우수한 3차원 지도를 만들 수 있다는 점이 놀라웠습니다.
[Advancing State-of-the-art Image Recognition with Deep Learning on Hashtags Yixuan Li, Research Scientist at Facebook AI]
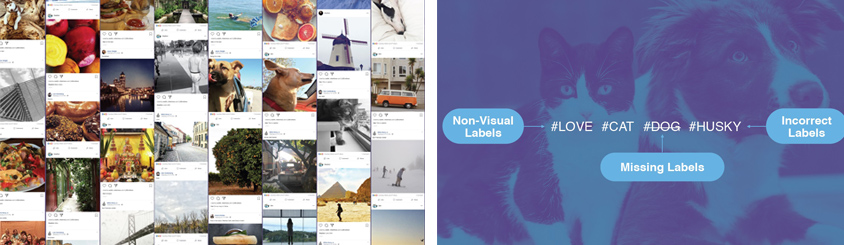
Facebook은 매일 업로드되는 수십억 개의 사진과 Image classification 인공 신경망의 학습 데이터로 쓰기 위한 방법을 고민했습니다. 실제 이러한 수많은 이미지들을 Supervised learning을 하기 위해 일일이 정답인 Label을 매칭하는 것은 불가능에 가깝습니다. 그래서 이를 해결하기 위해 위해 Label 값으로 사진과 함께 등록되는 Hashtag 값을 이용하기로 했습니다. 그러나 Hashtag에는 noise 값이 섞여있는 경우가 많습니다. 즉, 이미지를 설명하는 추상적이거나 상관없는 문맥이 포함될 수 있다는 뜻입니다.
이를 해결하기 위해 추려진 Hashtag에 대해 ImageNet의 Label에서 천오백 개의 라벨과 동의어를 매칭하였고, WordNet에서 1억 7천개의 동의어 명사를 매칭하여 Noise를 걸러냈습니다. 이렇게 정제된 Hashtag와 이미지는 사람이 임의로 Label 매칭을 한 것이 아니기 때문에, Weakly-supervised learning이라고 명명했습니다. 매일 인터넷에 업로드 되는 수많은 사진을 이러한 방식으로 학습시키면, 인공 신경망의 추론 성능을 크게 끌어올릴 수 있습니다. Facebook은 Hashtag 정보를 바탕으로 사진의 Context semantic captioning에도 적용할 예정이고, 나아가 Image segmentation의 능력을 높이는 데에도 활용할 예정이라고 합니다.
[A Deep Learning Model for Early Prediction of the Diagnosis of Alzheimer Disease from 18F-FDG PET scan of the Brain]
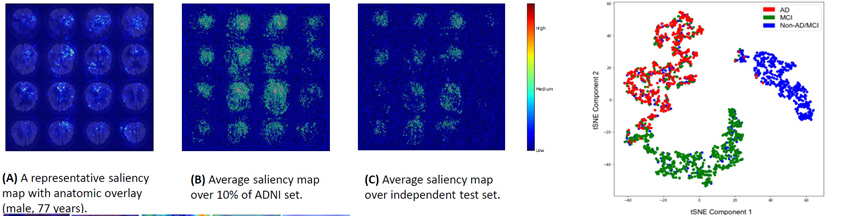
오늘날 미국에서는 5백만명이 넘는 사람들이 일명 ‘치매’로 불리는 뇌질환인 알츠하이머로 고통 받고 있고, 연간 2천억달러 이상이 이 질병으로 인해 직/간접적으로 소모된다고 합니다. UCSF Mediacl Center의 Sohn 박사는 18-FDG-PET Scan을 사진 분석을 인공 신경망을 통해 수행해서 알츠하이머의 조기 진단률을 높일 수 있는 지 연구했습니다. 연구진은 처음에는 3D Modeling 된 이미지로 학습을 시작했지만, 단층 촬영된 2D 이미지로 연구를 수행했을 때 결과가 더 좋게 해당 이미지를 활용했다고 하였습니다. 모델은 Google의 InceptionV3 인공 신경망 모델을, 가중치는 ImageNet에서 학습된 것을 바탕으로 UCSF Medical Center의 PET 자료를 학습시켰습니다.
이후 성능 분석 시, Saliency Map을 통해 추론 시 참고된 이미지의 영역을 확인한 결과 학습된 인공 신경망은 뇌의 특정 영역을 보는 게 아니라 뇌의 전반적인 부분을 모두 본다는 것을 알게 되었고, 이는 알츠하이머가 뇌의 거의 모든 부분에서 발병할 수 있다는 가설과 일치하였습니다. 또한, t-SNE 검증을 통해 진단 결과가 알츠하이머 이외의 다른 뇌질환(경도인지장애, 그 외의 질환)들과 구분되는 군집을 생성함을 알 수 있었다고 합니다. ROC curve를 통해 독립적인 외부 자료를 통해 추가 성능을 검증하였고, 기존의 방사선과 의사의 추정보다 정확도와 사전 예측에서 높은 성능을 보여주었다고 합니다. 향후 혈액 검사와 활용하여 알츠하이머 사전 진단율의 정확도를 높이기 위한 계기가 되길 기대합니다.
[ Brand is Beyond Logos ? Understanding Visual Brand, eBay Robinson Piramuthu, Chief Scientist of Computer Vision at eBay Inc.]

우리가 어떤 물건을 보고 그 물건의 브랜드를 예측할 때, 우리(사람)는 물건의 어떤 부분을 중심적으로 관찰합니까? 인공 신경망이 같은 작업을 하게 된다면 사람과 비교해서 어떠한 방식으로 결과를 도출하게 될까요? eBay는 서비스에 등록된 물건들의 Image Classification 과정을 통해 브랜드를 분류하는 과정에서 학습된 인공 신경망의 뉴런을 분석하면서 얻은 경험을 공유했습니다. 이들은 물건의 Image가 인공 신경망을 통과하여 결과를 도출하는 과정에서 어떤 뉴런이 어느 세기로, 어느 범위로 활성화 되었는지를 Reverse Engineering을 통해 관찰했습니다.
이 과정에서 어떤 상품은 제품 전체의 패턴과 디자인을 보기 위한 뉴런이 활성화되었고, 어떤 상품은 특정 영역에 위치한 로고를 보기 위한 뉴런이 활성화되었습니다. 즉 각 뉴런은 각 경우에 따라 Generalist, 또는 Specialist로 동작함을 알 수 있었으며, 이는 사람이 물건을 보고 특정한 디자인이나 로고를 통해 브랜드를 인식하는 과정과 매우 유사했습니다. Piramuthu는 이러한 뉴런의 특성과 행동을 올바르게 이해하는 것이 인공 신경망 모델의 개별 특성화, 예측의 편향성 제거, 모델의 성능 개선의 토대가 됨을 강조했습니다. 신경망의 성능이 발전함과 동시에 인공 신경망의 시각화와 이에 대한 통찰을 얻는 방법들이 점점 중요해 지고 있음을 깨달을 수 있었습니다.
[ How AI Can Empower the Blind Community, Anirudh Koul, Head of AI & Research at Aira ]

Aira는 시각장애인을 위한 AI Assistant를 소개했습니다. 해당 솔루션은 Image recognition, semantic image captioning, text-to-speech 기술을 통해 실시간으로 주변 이미지를 분석하여 이를 voice assistant가 읽어주는 형태입니다. Aira는 이러한 Assistant를 통해 장애인들이 느끼는 정상인과의 괴리를 극복함으로 장애인들이 더 다양하고 높은 수준의 활동을 하게 해 줄 수 있을 뿐 아니라, 궁극적으로 직/간접적인 사회적 비용 또한 감소시킬 수 있다고 주장하였습니다. 특히 발표자였던 Koul은 타자기, 전화기 등의 위대한 발명이 발명자의 가족이 겪는 장애를 극복하기 위한 시도에서 시작된 것이었다고 하면서, 조부가 노화로 인해 시력을 잃게 되어 본인을 알아볼 수 없게 된 것에 큰 슬픔을 느꼈던 것이 연구의 계기가 되었다고 설명했습니다.
Assistant를 통해 시각장애인들이 사람의 도움을 받지 않고도 길거리의 상점 상호를 읽을 수 있고, 외국어로 된 드라마의 자막을 읽을 수 있으며, 상점에서 제품 가격이 얼마인지를 바코드를 통해 읽을 수 있다고 하였습니다. Aira는 현재 앱 형태의 솔루션을 Mobile GPU의 발전과 Battery의 효율화에 힘입어 궁극적으로는 Smart glass 형태의 device로 개발하는 것을 목표로 하고 있습니다. 또한 다양한 상황과 인공 신경망 학습을 위한 Data augmentation은 자원봉사자들의 도움을 많이 받고 있다고 합니다. 개인적으로는 빠른 시일 내 확산이 가능한 솔루션 중 하나라고 생각이 들었고, 기술을 다루는 발표임에도 불구하고 듣는 내내 마음이 따뜻해 지는 느낌을 받았습니다.
[ OSscar, AI for Zero Waste, Hassan Murad, CEO, Intuitive AI ]
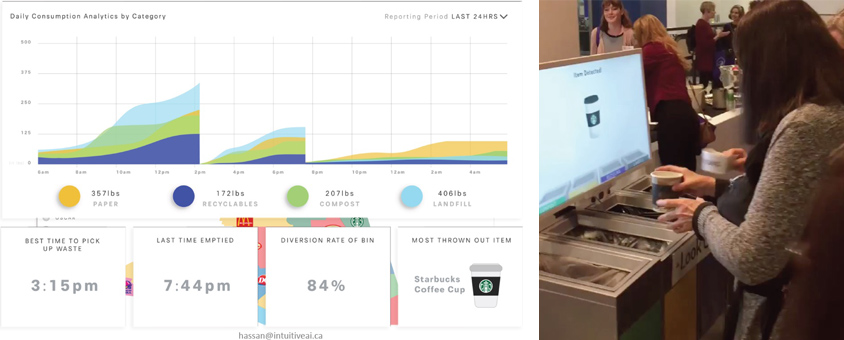
현재 전 세계의 쓰레기 발생량이 폭발적으로 증가하고 있는데, 쓰레기 발생량을 줄이기 위한 재활용 처리와 관련해서 아직도 많은 비효율성이 존재하는 상황입니다. 그나마 재활용 쓰레기 중에서도 2% 정도만 재활용이 가능하고, 나머지는 오염, 재활용 분류 과정 자체의 실수 등과 같은 문제들로 인해 활용이 불가능하다고 합니다. Intuitive AI는 이를 해결하기 위해 재활용 쓰레기 Assistant인 OSscar 모듈을 선보였습니다. OSscar는 Smart Machine Learning과 Computer Vision 기술을 이용한 자칭 ‘똑똑한 쓰레기통’으로, 카메라 비디오 입력으로 실시간 Object detection/recognition을 수행하여 들고 온 쓰레기를 어느 항목에 버려야 하는지를 빠르게 안내해 줍니다. 또한 카메라 비디오로 인식 처리를 하기 전, 초음파를 통해 Scene analysis를 수행, 실제 카메라가 분석할 때는 사용자의 얼굴을 Data anonymization(익명) 처리해 프라이버시도 보장하도록 배려하였습니다.
Intuitive AI는 OSscar를 통해 분리수거의 정확도를 높일 수 있을 뿐 아니라, 쓰레기통의 수거 시기를 정확하게 추천할 수 있고(Operational insight), 마케팅 분석을 위한 귀중한 자료(Marketing insight)로 기업에서 활용할 수 있을 것이라고 언급하였습니다. 여담으로, 발표자인 Murad는 OSscar가 사람들로 하여금 쓰레기 분리 수거 문제에 더 관심을 가질 수 있게 할 수 있다고 하면서, 많은 AI 기술이 인간의 사고/행동방식에 좋은 영향을 줄 수 있을 것이라고 스스로 평가하였습니다. 해당 솔루션은 공공 이익과 기업 이익을 모두 충족시킬 수 있는 좋은 사례로 보여졌습니다.
Stop publishing, and start transforming people’s lives with technology !"
2017년 AI Frontiers 컨퍼런스에서 AI Guru 중 한명인 Andrew Ng 교수는 발표도중 언급한 문장이라고 합니다. 결국 이론과 연구에 치우치기 보다, 실제 적용될 수 있는 AI 모델을 만들어 인류의 삶을 더욱 윤택하게 하는 데 노력을 해야 한다는 뜻인데, 이번 컨퍼런스를 통해 AI가 적용되고 있는 사례가 이전보다 훨씬 구체화되고 다양해졌다는 느낌을 받을 수 있었습니다.
향후 몇 년 사이에 기존의 Machine Learning 알고리즘 기법들이 인공 신경망에 기반한 해법들로 대체될 것이라는 예측이 있습니다. 그만큼 Computing Power가 증가하고 그에 대한 비용이 점차 감소하면서, 많은 엔지니어들이 자신의 Domain에 맞게 쉽게 AI를 가져다 쓸 수 있게 될 것으로 보입니다. 또한 기존의 Supervised learning 위주의 AI가 점차 Reinforcement learning 중심으로 급격하게 옮겨가고 있음을 느낄 수 있었습니다. 하루게 다르게 변화하는 AI 세계에서 앞으로 어떠한 이론이, 어떠한 솔루션이 등장해서 우리의 생활을 더욱 흥미진진하게 해 줄지 기대됩니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 개발실
mVoIP 서비스의 UI 개발, 비즈니스 로직 개발을 거쳐 현재 삼성 그룹의 Video Conference 솔루션인 Knox Meeting의 통신 엔진을 개발하고 있습니다. 머신러닝을 통해 Video Conference의 품질을 개선할 수 있는 다양한 방법을 고민 중입니다.