

행사소개
필자는 [Deep Learning Summit 2019, “Deep Learning Stage”]를 기고한 정지원 프로와 함께 1월 24일부터 25일까지 2일간, 샌프란시스코에서 열린 Deep Learning Summit 2019 행사에 참석했습니다. 본 컨퍼런스는 Deep Learning REWORK AI관련 최신 기술 연구내용을 발표하고 적용 사례를 공유하기 위한 행사입니다. 이번 컨퍼런스는 Machine Learning, Deep Learning, Industrial Automation, Healthcare, Robotics, AI Assistant 등으로 구성되었으며, 필자는 AI Assistant 중 Conversational AI (대화형 인공지능)에 대한 내용을 중심으로 소개하겠습니다.
참석세션 둘러보기
[Open-Ended Challenges in Dialog Systems]
우버 AI팀의 연구원인 Chandra Khatri가 open-ended형 대화에 있어 Dialog system이 가지는 한계를 해결하는 방법과 대화 내 민감한 표현을 감지하는 방법에 대해 공유 하였습니다.
Language Understanding에 관한 많은 연구들이 있지만 의견 등을 묻는 open ended의 대화의 경우 도메인도 정해져 있지 않을 뿐 아니라 대부분의 문장들이 구조화 되어있지 않기 때문에 기존의 방식처럼 해당 문장에서 intent(API to call)와 slot(argument for API)를 구분하는 것은 여전히 어려운 문제입니다. 이러한 어려움을 해결하기 위해 "Topic and dialog act based approach"에 대해 소개하였습니다.

대화 내에서 주제, Dialog act, 키워드를 인식하고 그것과 관련된 글을 찾아 학습한 뒤, 논리적인 피드백을 만들어 내는 방식인데 이 방식을 활용한 많은 팀들이 Alexa prize에서 좋은 성과를 냈다고 합니다.
다음으로는 공격적이고 민감한 표현을 감지하는 방법에 대해 이야기 했는데 대부분의 대화형 시스템에서는 Blacklist를 관리하여 이 단어들을 사용하지 않거나 마스킹하여 표현하는데 같은 표현도 나라, 문화에 따라 다르게 받아들여질 수 있기 때문에 이 모든 가능성들을 학습데이터로 만드는 것이 어렵다고 합니다.
이러한 문제를 해결하기 위해 연사는 "Bootstrapping data with semi-supervision" 학습 방식을 고안해 냈는데 해당 방식은 두 단계로 이루어져있습니다. 먼저 blacklist에 있는 단어들을 바탕으로 민감한 세부 영역를 정의하고 해당 키워드로 Reddit이라는 소셜뉴스의 카테고리를 민감한 것과 민감하지 않은 것으로 분류 합니다. 이렇게 분류된 글들의 공통점을 찾아내어 BiLSTM 방식으로 classifier를 학습시킨다고 합니다.
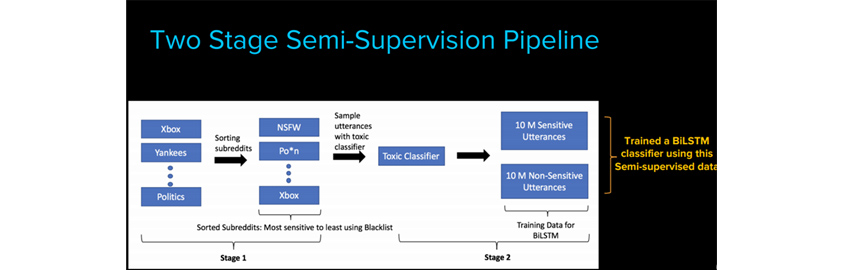
해당 모델이 사람이 판단하기 힘든 민감한 내용도 탐지할 정도의 정확성을 보인다는 점이 인상 깊었습니다.
[On-device Neural Networks for Natural Language Processing]
Google의 Engineering manager인 Zornitsa Kozareva는 디바이스 내 머신러닝 모델 임베딩에 대해 발표하였습니다. 디바이스에만 존재하고 동작하는 모델을 만들게 되면 서버와의 연결상태에 영향을 받지 않아 서비스 지연을 막을 수 있을 뿐만 아니라 데이터가 디바이스 밖으로 나올 필요가 없기 때문에 프라이버시 이슈를 완화 시킬 수 있다는 점이 흥미로웠습니다.
일반적인 스마트기기는 아래의 그림과 같이 작동합니다.

스마트 스피커에게 "거실에 있는 불 켜주세요" 라고 말하면 해당 명령어는 Google의 cloud로 보내져서 명령어의 해석이 이루어지고 난 뒤 거실에 있는 전등에 명령이 전해져 불이 켜지게 되는 것입니다. 네트워크 문제로 작동지연을 경험하기도 하는데 디바이스에 머신러닝 모델을 직접 내장시킨다면 이러한 문제들이 해결 될 수 있는 것입니다.
2020년에는 IoT로 모든 것이 연결된 세상이 되어 전자레인지 등의 디바이스에 음성으로 명령을 직접 전달하게 될 것이라고 하는데, 이것이 이루어지기 위해서는 작은 디바이스에도 내장되어 작동할 수 있는 Lightweight NLP가 필요합니다.
이를 위해 구글에서는 SGNN (Self Governing Neural Networks)이라고 불리는 특별한 인공신경망을 고안해 냈다고 합니다.
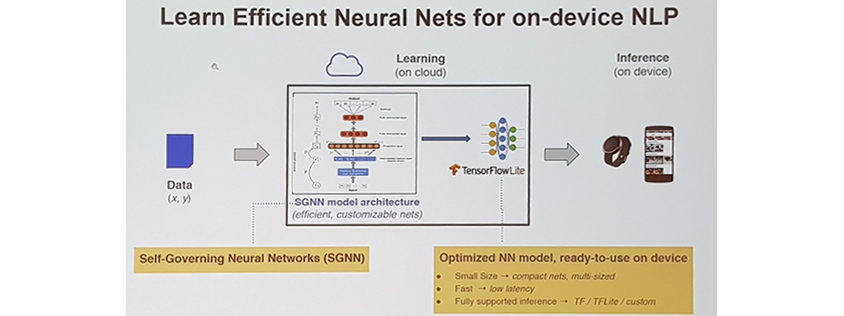
SGNN은 낮은 수준의 문장의 의미를 파악하여 적은 메모리와 컴퓨팅 파워로도 작동할 수 있는 컴팩트한 모델을 만들어 내는데 SGNN의 자세한 원리는 연사의 논문을 통해 확인해보실 수 있습니다. (논문링크: https://aclweb.org/anthology/D18-1105 )
해당 모델은 다양한 언어로 task를 높은 수준으로 수행하고 기존 on-device의 CNN, RNN 보다 더 좋은 성과를 보이고 있다고 합니다.
[End-to-End Conversational System for Customer Service Application]
Amazaon Customer Service 의 Manisha Srivastava는 아마존 Conversational System의 정확도 향상을 위한 아마존의 노력에 대해 공유하였습니다.
현재 amazon prime의 챗봇(Chatbot)은 자연어를 이해할 수 있는 능력만 있고 봇이 취하는 액션은 다 백단에 룰형태로 정의되어있는 workflow를 참조하여 이루어지는 것이라고 합니다. 해당 방식으로는 예상되지 않은 질문에 반응 할 수 없고 학습능력이 없기 때문에 챗봇 자동화에 한계가 있습니다.
이러한 문제를 해결하기 위해 아마존에서는 작년부터 end to end 학습모델를 구축하고 있다고 합니다. 고객과의 대화이력과 고객의 프로파일을 input으로하고, 고객에게 반응한 텍스트와 액션을 output 으로 주어 모델을 학습시키는 방식이며 Response generation model, Response ranking model로 2개의 모델로 나누어 실험해 보았다고 합니다.
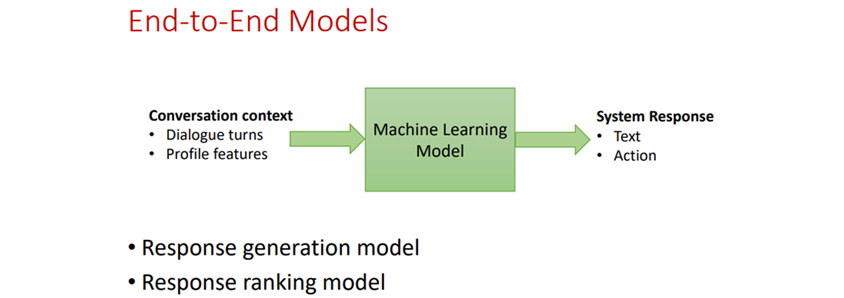
Response generation model은 상황에 맞게 응대내용을 만들어 내는 것이고 Response ranking model은 반응리스트가 주어지고 그 중에 선택하여 응대하는 것인데 실험결과 Generative models 이 ranking models 보다 좋은 결과를 보였지만 안전하고 일반적인 행동을 기대하기에는 부족함이 있었다고 합니다.
다음으로는 아마존의 챗봇을 평가방식에 대해 이야기 해 주었습니다. 챗봇의 응대결과를 자동으로 평가하는 것은 쉽지 않아서 현재로서는 봇의 응대내역을 상담원이 실시간으로 확인하고 봇의 응답 또는 해결책을 최종 승인, 반려한다고 합니다.
아마존에서 챗봇 트레이닝 시 평가에 사용하는 매트릭스는 아래와 같습니다.
• 전체 대화 횟수
• 전체 대화에서 봇이 응답한 횟수
• 봇이 제시한 해결책 중 승인된 건의 수
• 봇의 응답이 반려 되기 전까지 봇이 이끌어간 대화의 길이
• 봇이 제시한 해결책 문장의 단어의 수
* 장황하고 매우 자세한 문장으로 해결책을 제시할 경우 틀린 해결책일 가능성이 더 크다고 합니다.
아마존의 향후 목표는 응대 방식에 대한 고객의 선호를 파악하여 개인화된 응대를 제공하고 비즈니스 정책변화를 자동으로 이해하여 적용할 수 있는 완전히 자동화된 챗봇을 만드는 것이라고 하네요.
느낀점
다양한 기업들의 대화형 시스템의 정확도, 효율성 향상을 위한 노력과 NLU (Natural Language Understanding) 의 자세한 기술을 직접 들을 수 있어서 좋았습니다. NLP (Natural Language Processing) 기술의 다양한 사례 또한 흥미로웠습니다. 인간과의 대화에 어색함이 없고 더 많은 업무를 수행 할 수 있는 human like 대화형 시스템이 탄생하기를 기대해봅니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 금융IT사업부 카드IT혁신팀
8년 간 삼성카드 시스템을 운영, 개발해 온 금융시스템 전문가입니다.