
General AI vs Narrow AI
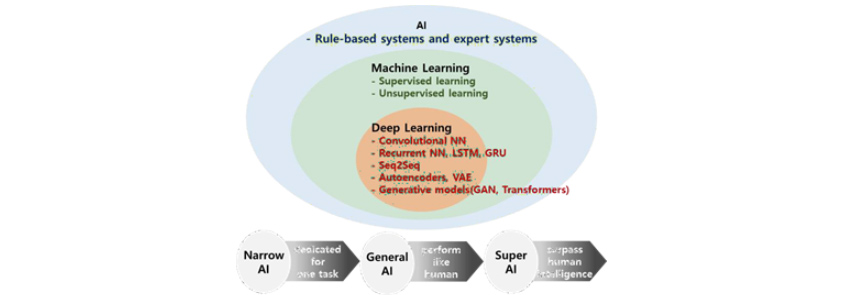
Trí tuệ nhân tạo (Artificial Intelligence, AI) có nghĩa là việc sử dụng hệ thống máy tính để mô phỏng hoặc thực hiện các công việc mang tính trí tuệ của con người. Trí tuệ nhân tạo thời kỳ đầu chủ yếu thực hiện các nhiệm vụ lặp đi lặp lại đơn giản theo các quy tắc và logic được xác định trước dựa trên nền tảng tri thức chuyên môn của con người. Học máy (Machine Learning) xuất hiện như một lĩnh vực con của trí tuệ nhân tạo, cung cấp cái nhìn sâu sắc bằng cách học các mô hình và phân bố mang tính xác suất mà con người khó có thể hiểu hoặc phân biệt dễ dàng, đồng thời dự đoán tương lai để giúp đưa ra quyết định. Học sâu (Deep Learning), được phát triển thêm một bước nữa từ học máy, có thể xử lý thông tin phức tạp và chuyên sâu hơn trên nền tảng mạng lưới thần kinh nhân tạo được tạo ra dựa trên cấu trúc của hệ thần kinh con người. Các tính năng của trí tuệ nhân tạo được cải tiến liên tục như vậy
Tháng 3 năm 2016 (khoảng thời gian này 7 năm trước), đã xảy ra một sự kiện mang tính cách mạng trong lĩnh vực trí tuệ nhân tạo khiến cả thế giới chú ý. Việc trí tuệ nhân tạo AlphaGo, được phát triển bởi Google DeepMind, đã đánh bại kỳ thủ cờ vây vô địch thế giới Lee Se-dol, là thời khắc lịch sử giúp công bố rộng rãi tới công chúng sự đổi mới và phát triển của công nghệ trí tuệ nhân tạo. Trận đấu này là một ví dụ rõ ràng cho thấy khả năng của Narrow AI (Trí tuệ nhân tạo hẹp; Weak AI, Trí tuệ nhân tạo yếu), được thiết kế để thực hiện các nhiệm vụ cụ thể và giải quyết các vấn đề chuyên biệt trong phạm vi giới hạn. Bởi vì Narrow AI đã học trò chơi cờ vây, được chuyên môn hóa về một lĩnh vực cụ thể nên có thể chơi cờ vây ở mức độ đáng kinh ngạc như AlphaGo, nhưng lại không thể thực hiện các nhiệm vụ không liên quan khác như hiểu ngôn ngữ, phân loại hình ảnh, nhận dạng giọng nói, lái xe tự động và dự đoán nhu cầu. Ngược lại, General AI (Trí tuệ nhân tạo tổng quát; Strong AI, trí tuệ nhân tạo mạnh) được thiết kế để nhận biết/học hỏi/thực hiện tất cả các nhiệm vụ trí tuệ mà con người có thể thực hiện trong nhiều lĩnh vực khác nhau, nhưng nó vẫn còn là một khái niệm lý thuyết.
AI tạo sinh (Generative AI) xuất hiện cùng với sự phát triển của học sâu, là một thuật toán có thể được sử dụng để tạo nội dung mới như âm thanh, video, hình ảnh, văn bản, code và mô phỏng dựa trên các mẫu hiện có. ChatGPT, được phát triển bởi OpenAI, là một kiệt tác được tạo ra khi công nghệ trí tuệ nhân tạo tiếp tục phát triển trong một thời gian dài trong lĩnh vực AI tạo sinh và đang trở thành một bước ngoặt chuyển từ Narrow AI sang General AI. Mục tiêu cuối cùng của trí tuệ nhân tạo là đạt được Super AI, vượt qua cả trí tuệ con người.
ChatGPT được thiết kế chủ yếu cho tác vụ xử lý ngôn ngữ tự nhiên (Natural Language Processing, NLP), nhưng có thể áp dụng cho nhiều tác vụ hơn so với Narrow AI. Tuy nhiên, nó vẫn chưa phải là một General AI đúng nghĩa. Điều này là do kiến thức và khả năng của ChatGPT bị giới hạn bởi phạm vi dữ liệu đào tạo được xác định trước và khả năng thực hiện của nó trong các tác vụ khác tương đối yếu so với lĩnh vực ngôn ngữ.
Trên hành trình hướng tới General AI, sự ra mắt của ChatGPT đang đẩy nhanh việc mở rộng các lĩnh vực có thể hỗ trợ các nhiệm vụ của con người nhờ những tiến bộ trong công nghệ trí tuệ nhân tạo và nó có ý nghĩa ở chỗ cho thấy tiềm năng lớn hơn các mô hình AI khác đã được ra mắt cho đến nay.
 [Hình 1] Các khái niệm có trong trí tuệ nhân tạo
[Hình 1] Các khái niệm có trong trí tuệ nhân tạo
- rule-based system and expert systems
- supervised learning
- unsupervised learning
- rule-based system and expert systems
- convolutional NN
- recurrent NN, LSTM,GRU
- seq25eq
- autoencoders, VAE
- generative models(GAN, Transformers)
- Narrow AI -> General AI -> Super AI
Trí tuệ nhân tạo (AI) là lĩnh vực nghiên cứu - phát triển các phương pháp luận cho hệ thống thông minh. AI thời kỳ đầu như là nền tảng quy tắc hoặc hệ thống chuyên gia, hoạt động dựa trên các quy tắc được xác định trước hoặc trên nền tảng tri thức chuyên môn của con người. Học máy xuất hiện như một lĩnh vực con của AI và đã phát triển qua nhiều năm, học sâu là một khái niệm con của học máy. Những tiến bộ trong học sâu đã dẫn đến những cải thiện đáng kể về tính năng của AI. Hiện tại, trong số các giai đoạn phát triển AI, nó đang nằm giữa Narrow AI và General AI. Tương lai của nghiên cứu AI nhằm mục đích đạt được không chỉ General AI mà còn cả Super AI, tạo ra những khả năng chưa từng có trong tác động tương hỗ giữa con người và máy móc.
Sau khi OpenAI ra mắt ChatGPT (ngày 30 tháng 11 năm 2022), Google đã chạy thử bản demo tại buổi thông báo ra mắt Bard (ngày 6 tháng 2 năm 2023). Và sau đó, Google đã công bố kế hoạch áp dụng AI một cách toàn diện cho dòng sản phẩm Workspace của mình (ngày 15 tháng 3 năm 2023). Hai ngày sau đó, Microsoft khi này đang hợp tác với OpenAI, cũng công bố kế hoạch ra mắt Microsoft 365 Copilot, một phần mềm áp dụng AI cho tất cả các công cụ tăng năng suất làm việc của hãng (ngày 16 tháng 3 năm 2023). Trong vòng chưa đầy 4 tháng, sự cạnh tranh giữa các công ty công nghệ lớn toàn cầu xung quanh công nghệ GPT ngày càng gay gắt và ngành IT toàn cầu đang nỗ lực phát triển các mô hình kinh doanh kết hợp công nghệ GPT (Generative Pre-trained Transformer). Sự kiện ra mắt ChatGPT sẽ được ghi nhận là sự kiện lịch sử đánh dấu cột mốc quan trọng trong bước phát triển của trí tuệ nhân tạo.
| Ngày | Nội dung chi tiết |
|---|---|
| ’22.11.30 | OpenAI ra mắt ChatGPT (GPT-3.5) |
| ’22.12.05 | Số người dùng ChatGPT được kích hoạt hàng ngày (DAU) đã vượt quá 1 triệu người. |
| ’22.12.15 | OpenAI đưa watermark vào ChatGPT |
| ’22.12.25 | Số người dùng ChatGPT được kích hoạt hàng ngày (DAU) vượt quá 10 triệu người |
| ’22.12.26 | Google phát “Báo động đỏ” về ChatGPT |
| ’22.12.27 | Bespin Global đưa công nghệ GPT vào “HelpNow AI” |
| ’22.12.31 | Số người dùng ChatGPT được kích hoạt theo tháng (MAU) của tháng 12 vượt quá 57 triệu người |
| ’23.01.23 | Microsoft đầu tư bổ sung 10 tỷ USD vào OpenAI |
| ’23.01.31 | Số người dùng ChatGPT được kích hoạt theo tháng (MAU) của tháng 12 vượt quá 100 triệu người |
| ’23.02.01 | TwoBlock AI đăng ký bằng sáng chế liên quan đến phương pháp ứng dụng AI tạo sinh |
| ’23.02.03 | Naver công bố kế hoạch cho ra mắt “SearchGPT” vào nửa đầu năm |
| ’23.02.06 | Google công bố ra mắt Bard và chạy thử bản demo |
| ’23.02.07 | Microsoft công bố “Bing”, công cụ tìm kiếm có tích hợp ChatGPT |
| ’23.03.09 | Upstage ra mắt “AskUp”, kết hợp công nghệ OCR với ChatGPT |
| ’23.03.14 | OpenAI ra mắt ChatGPT (GPT-4) |
| ’23.03.15 | Google công bố kế hoạch áp dụng AI một cách toàn diện cho dòng sản phẩm Workspace của mình |
| ’23.03.16 | Microsoft công bố kế hoạch cho ra mắt Microsoft 365 Copilot, có ứng dụng AI trên các công cụ tăng năng suất làm việc |
| ’23.03.23 | OpenAI công bố hỗ trợ plugin ChatGPT |
ChatGPT là gì
ChatGPT là dịch vụ đối thoại AI (chatbot) được phát triển bởi OpenAI (một công ty nghiên cứu và phát triển do Sam Altman thành lập vào tháng 12 năm 2015 nhằm theo đuổi lợi ích của nhân loại thông qua trí tuệ nhân tạo) và dựa trên cấu trúc GPT. ChatGPT đã nhận được sự chú ý bùng nổ ngay khi ra mắt, thu hút được 1 triệu người dùng sau 5 ngày, khoảng 10 triệu người dùng trong 1 tháng và vượt qua 100 triệu người dùng được kích hoạt theo tháng (Monthly Active Users, MAU) trong 2 tháng. Trong trường hợp của các công ty IT khác, khi so sánh với thời gian để đạt được 1 triệu người dùng của Netflix (3,5 năm), Airbnb (2,5 năm), Facebook (10 tháng), Spotify (5 tháng), Instagram (2,5 tháng), iPhone (74 ngày), ta có thể thấy ChatGPT cực kỳ được yêu thích.
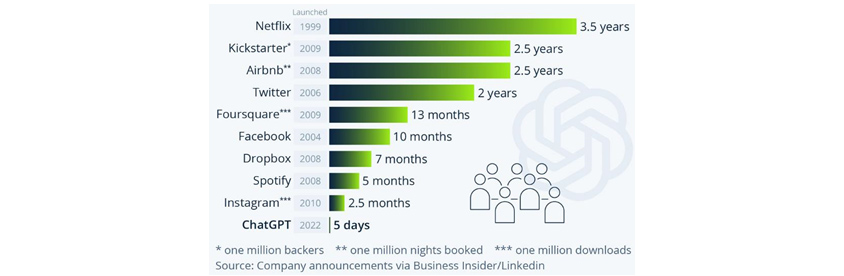 [Hình 2] Thời gian cần thiết để đạt 1 triệu người dùng theo nền tảng, nguồn:Katharina Buchholz, statista, 2023.1.24, 「ChatGPT Sprints to One Million Users」 (https://www.statista.com/chart/29174/time-to-one-million-users/)
[Hình 2] Thời gian cần thiết để đạt 1 triệu người dùng theo nền tảng, nguồn:Katharina Buchholz, statista, 2023.1.24, 「ChatGPT Sprints to One Million Users」 (https://www.statista.com/chart/29174/time-to-one-million-users/)
- Netflix - 1999 -3.5 years
- Kichstarter* - 2009 -2.5 years
- Airbnb** - 2008 -2.5 years
- twitter - 2006 -2 years
- Foursquare***- 2009 -13 months
- facebook - 2004 -10 months
- Dropbox - 2008 -7 months
- Spotify - 2008 -5 months
- Instagram*** - 2010 -2.5 months
- ChatGPT- 2022 -5 days
- *one million backers **one million nights booked ***one million downloads source company announcements via business insider/Linkedin
Các chatbot hiện tại hoạt động như một hệ thống dựa trên các quy tắc, chỉ đơn giản là làm khớp mẫu các từ khóa được trích xuất từ các câu hỏi với thông tin được lưu trữ trong DB, chỉ cho phép trò chuyện trong một phạm vi giới hạn. Mặt khác, ChatGPT hiểu ngữ cảnh đằng sau thông tin bề mặt và ghi nhớ các bản ghi chép cuộc trò chuyện trong quá khứ, cho phép truyền tải thông tin ở mức độ tương tự như nói chuyện trực tiếp với một người. Nếu chúng ta xem xét các ví dụ với mục đích cụ thể hơn, thì ChatGPT có thể thực hiện các tính năng như tạo văn bản (ví dụ: Lời bài hát, tiểu thuyết, thư điện tử, bản kế hoạch), phân tích cảm xúc (ví dụ: Phân loại đánh giá tích cực và tiêu cực của khách hàng), phân loại tài liệu (ví dụ: phân loại chủ đề bài báo tin tức, phân loại ý kiến khách hàng), tóm tắt văn bản, trích xuất từ khóa, biên dịch, Q&A, sửa ngữ pháp, viết mã lập trình, tạo bảng, v.v. Nhờ nhiều bài kiểm tra tính năng khác nhau sau khi ra mắt, nó đã vượt qua kì thi MBA của trường Wharton Mỹ, kỳ thi cấp giấy phép hành nghề bác sỹ và kỳ thi trường luật của Mỹ một cách dễ dàng, điều này chứng tỏ được năng lực thực hiện các công việc liên quan đến khả năng trí tuệ của con người.
| Tính năng | Nội dung chi tiết |
|---|---|
| Vượt qua kì thi MBA trường Wharton Mỹ | Đạt điểm từ B- đến B trong kỳ thi cuối kỳ môn “Quản lý vận hành”, một môn học bắt buộc |
| Vượt qua kỳ thi của trường Luật Minnesota Mỹ | Đạt điểm C+ trong bài kiểm tra, bao gồm 95 câu hỏi trắc nghiệm và 12 câu hỏi tiểu luận |
| Vượt qua Kỳ thi Cấp giấy phép Y tế Hoa Kỳ (USMLE) | Độ chính xác trên 50% trong tất cả các bài kiểm tra |
| Được liệt kê là đồng tác giả của một bài luận văn học thuật | ChatGPT được liệt kê là đồng tác giả của bài luận văn của Giáo sư Siobhan O'Connor trường Đại học Manchester tại Anh |
| Viết kịch bản quảng cáo | Viết kịch bản quảng cáo cho nhà mạng điện thoại Mint Mobile theo phong cách của ngôi sao điện ảnh Ryan Reynolds. |
Phát triển mô hình ngôn ngữ
ChatGPT là một kiệt tác được tạo ra thông qua sự phát triển không ngừng của trí tuệ nhân tạo và công nghệ học máy (Machine Learning) trong một thời gian dài trong lĩnh vực AI tạo sinh (Generative AI). AI tạo sinh là một thuật toán có thể được sử dụng để tạo ra nội dung mới như âm thanh, video, hình ảnh, văn bản, code và mô phỏng dựa trên các mẫu hiện có và gần đây đang nhận được sự quan tâm lớn trong việc phân tích ngôn ngữ và hình ảnh. Lĩnh vực AI tạo sinh đã có những đóng góp lớn nhỏ để phát triển đến trình độ hiện tại, nhưng ở đây sẽ tập trung giải thích các mô hình đóng vai trò là cột mốc quan trọng trong mô hình ngôn ngữ.
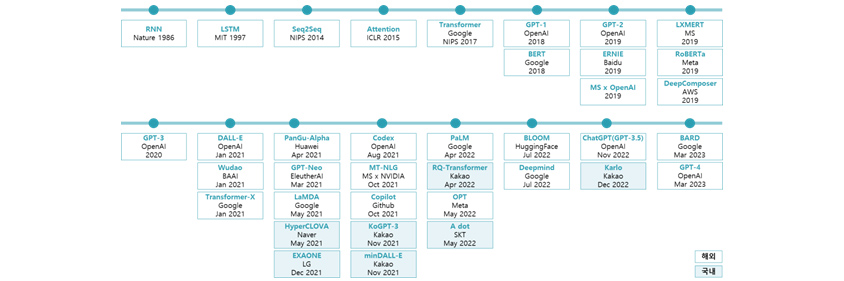 [Hình 3] Timeline của sự phát triển chính trong mô hình ngôn ngữ
[Hình 3] Timeline của sự phát triển chính trong mô hình ngôn ngữ
- RNN:Nabze,1986/LSTM:MIT,1997/SEQ@SEQ:NIPS,2014/Attention:ICLR,2015/Transformer:Google NIPS,2017/GPT-1:OpenAI,2018/GPT-2:OpenAI,2019/LXMERT:MS,2019//GPT-3:OpenAI,2020/DALL-E:OpenAI, Jan 2021/PanGu-Alpha:Hawai, Apr 2021/Codex:OpenAI,Aug 2021/PaLM:Google,Apr 2022/BLOOM:HuggingFace,Jul 2022/CHatGPT(GPT-3.5):OpenAI,Nov 2022/BARD:Google,Mar 2023
- BERT:Google,2018/ERNIE:Baidu,2019/RoBERTa:Meta,2019/Wudao:BAAI,Jan 2021/GPT-Neo:EleutheAI,Mar 2021/MT-NLG:MS x NVIDIA,Oct 2021/RQ-Transformer:kakao,Apr 2022s/Deepmind:Google,Jul 2022/Karlo:Kakao,Dec 2022
- MS x OpenAI,2019/DeepComposer:AWS,2019/Transformer-X:Google,Jan 2021/LaMDA:Google,May 2021/Copilot:Github,Oct 2021/OPT:Meta,May 2022/
- HyperCLOVA:Naver,May 2021/KoGPT-3:Kakao,Nov 2021/A dot:SKT,May 2022
- EXAONE:LG,Dec 2021/minDALL-e:Kakao,Nov 2021
Bằng cách dạy máy móc học các hiện tượng với các quy tắc phức tạp mà bộ não con người khó có thể nắm bắt trong nháy mắt, chúng tôi tìm cách nắm bắt các mô hình tồn tại bên trong của hiện tượng và dự đoán tương lai. Để đạt được điều này, chúng tôi đưa dữ liệu đã được nén những thông tin về hiện tượng vào mạng lưới thần kinh nhân tạo có cấu trúc tương tự hệ thống thần kinh của con người. Trong lúc dữ liệu di chuyển qua mạng lưới thần kinh nhân tạo, máy sẽ thực hiện quá trình tìm hiểu về dữ liệu bao gồm học luồng dữ liệu chung, các yếu tố có thể gộp chung và phân loại, thông tin cần thiết để nắm bắt mô hình và loại bỏ nhiễu. Và khi dữ liệu đến điểm cuối cùng của mạng lưới thần kinh, máy sẽ đưa ra giá trị dự đoán dựa trên thông tin đã học, nếu khác với câu trả lời đúng thì dữ liệu (sai số) sẽ được gửi trả về và phương pháp học sẽ được điều chỉnh lại. Lặp lại quá trình này cho đến khi trả lời đúng và đạt được mục tiêu đã đề ra. Quá trình gửi dữ liệu tiến và lùi để máy có thể học được gọi là Mạng thần kinh truyền thẳng và truyền ngược (Feedforward Neural Networks and Backpropagation, FNNs, 1980s).
Khi dữ liệu như âm thanh hoặc văn bản theo thứ tự trước sau đưa vào theo tuần tự, mạng lưới thần kinh truyền thẳng cho phép dữ liệu tiếp tục truyền theo một hướng và máy cũng tính toán giá trị dự đoán dựa vào dữ liệu đầu vào này. Tuy nhiên, khi tính toán dự báo dựa trên thông tin về dữ liệu mới đưa vào, nếu tham khảo cả thông tin đã đi qua ngay trước đó thì có thể chính xác hơn. Mạng thần kinh hồi quy (Recurrent Neural Networks, RNNs, những năm 1980-1990) được thiết kế để có cấu trúc vòng tròn cho phép thông tin đã vào và đi qua trước đó quay trở lại mạng. Bằng cách đào tạo mạng lưới thần kinh dựa trên sự hiểu biết về ngữ cảnh trước sau thông qua xem xét cả ký ức về thông tin trong quá khứ và thông tin mới, những dự đoán về cả quá khứ và hiện tại đều có thể thực hiện được. Nó phù hợp để xử lý dữ liệu tuần tự thay đổi theo thời gian, chẳng hạn như dữ liệu chuỗi thời gian, nhận dạng giọng nói và xử lý ngôn ngữ tự nhiên.
Bây giờ, dựa trên cấu trúc RNN, giá trị hiện tại cũng có thể được dự đoán bằng cách tham khảo thông tin đã đưa vào trong quá khứ. Tuy nhiên, do phải tham khảo không chỉ những thông tin đưa vào ngay trước đó mà còn phải tham khảo cả những thông tin đã đưa vào từ lâu nên xảy ra tình huống dữ liệu bị dồn lại theo thời gian làm cho trí nhớ bị mất đi cũng như khả năng học kém đi. Để giải quyết vấn đề này, Bộ nhớ dài-ngắn hạn (Long Short-Term Memory, LSTM, 1997), là một dạng của RNN, được thiết kế để học hiệu quả ngay cả dữ liệu tuần tự dài bằng cách phân biệt và kiểm soát thông tin quan trọng cần được ghi nhớ lâu dài với thông tin có thể quên.
Có hai cấu trúc RNN, đó là (1) “bộ mã hóa (encoder)”, cấu trúc RNN tìm hiểu dữ liệu đầu vào, cô đọng và chỉ xử lý thông tin và bối cảnh cần thiết và (2) Seq2Seq (Sequence to Sequence, 2014) là một loại mạng thần kinh được xây dựng bằng cách kết hợp “bộ giải mã (decoder)”, một cấu trúc RNN nhận thông tin cô đọng về quá khứ và hiện tại từ bộ mã hóa và tính toán giá trị dự đoán. Việc cấu hình bộ mã hóa và bộ giải mã theo cách này cho phép hiểu rõ hơn về mối quan hệ phức tạp giữa dữ liệu đầu vào và đầu ra, tạo thuận lợi cho các tác vụ như dịch máy. Tất nhiên, tại thời điểm này, các RNN tạo nên bộ mã hóa và bộ giải mã có thể được áp dụng trong cấu trúc LSTM và cũng có thể được xếp chồng lên nhau dưới dạng nhiều lớp khối.
Do thất thoát xảy ra khi thông tin được nén trong mô hình Seq2Seq nên tính năng của mô hình sẽ giảm khi thông tin đầu vào dài hơn. Để giải quyết vấn đề này, cơ chế Attention (Chú ý) (2014) giúp cải thiện tính năng của mô hình Seq2Seq bằng cách cho phép chỉ tập trung sự chú ý có chọn lọc vào những phần cần thiết của thông tin đầu vào tuần tự. Nói cách khác, mỗi khi một từ được xuất ra, toàn bộ câu đầu vào sẽ được tham chiếu. Nhưng lúc này, thay vì kiểm tra tất cả các từ trong câu đầu vào với mức độ quan trọng như nhau, nó sẽ chú ý nhiều hơn một chút đối với những từ có liên quan nhiều đến từ sẽ được xuất ra. Do đó với mỗi lần xuất ra, nhóm các từ có tỉ trọng lớn trong câu đầu vào sẽ liên tục thay đổi.
Mô hình ngôn ngữ nền tảng Transformer
Năm 2017, Google công bố luận văn có tiêu đề là “Attention is all you need” và giới thiệu mô hình Transformer ứng dụng cơ chế Attention. Transformer cho thấy tính năng vượt trội hơn hẳn mô hình trước đó và là mô hình ngôn ngữ phát triển với tốc độ nhanh chóng trong lĩnh vực AI tạo sinh từ lúc đó. Xem xét rằng hầu hết các mô hình ngôn ngữ hiện đang được sử dụng đều đang mở rộng dựa trên Transformer, có vẻ như nó sẽ tiếp tục đóng vai trò trung tâm cho đến khi có phương pháp luận đổi mới hơn được đề xuất.
Transformer (2017) cũng có cấu trúc bộ mã hóa-bộ giải mã phản ánh mối quan hệ giữa thông tin đầu vào và thông tin đầu ra giống như mô hình Seq2Seq, nhưng điểm khác biệt lớn nhất giữa hai mô hình là cách chúng tiếp nhận thông tin. Trong khi RNN nhận thông tin tuần tự từng thông tin một và sử dụng cấu trúc vòng tròn để gợi lại ký ức trong quá khứ thì Transformer nhận tất cả thông tin cùng một lúc rồi quét và kiểm tra thông tin cần tập trung thông qua cơ chế Attention. Đầu tiên, thông qua cơ chế Self-attention của bộ mã hóa, mối quan hệ và tầm quan trọng của từng từ với các từ khác trong toàn bộ câu đầu vào được xác định và mã hóa dưới dạng thông tin ngụ ý. Bộ giải mã nhận thông tin này không chỉ đo lường mức độ liên quan của từ được xuất ra hiện tại với từng từ trong câu đầu vào thông qua cơ chế Attention của bộ mã hóa-bộ giải mã, mà còn đo lường mối liên quan giữa các từ đầu ra đã xuất từ trước cho đến nay thông qua cơ chế Self-attention của bộ giải mã. Nói cách khác, mối liên quan giữa các từ trong câu đầu vào, mối liên quan giữa câu đầu vào và từ đầu ra và mối liên quan giữa các từ trong câu đầu ra đều được kiểm tra. Dựa vào ba loại cơ chế Attention này, có thể đưa ra kết quả có mức độ liên quan cao đến thông tin đầu vào và do cơ chế Attention này được xử lý song song nên lượng lớn dữ liệu có thể được xử lý một cách hiệu quả. Tham khảo thêm, vì RNN nhận tuần tự từng thông tin một nên không cần phải xử lý và lưu trữ riêng thông tin thứ tự từ trong một câu và chỉ cần nhớ lại ký ức về thông tin trong quá khứ thông qua cấu trúc vòng tròn. Ngược lại, Transformer nhận tất cả thông tin cùng một lúc và bảo toàn thông tin thứ tự (Positional Encoding) bằng cách xử lý riêng biệt và kết hợp thông tin vị trí từ trong một câu.
BERT (Bidirectional Encoder Regressionations from Transformers, 2018) là một phương pháp luận được Google thiết kế để đào tạo trước các cách biểu diễn ngôn ngữ dựa trên mô hình Transformer và là mô hình được đào tạo trước với khối lượng lớn dữ liệu văn bản. Đúng như tên gọi, đặc điểm chính của nó là có khả năng hiểu ngữ cảnh hai chiều, giúp dễ dàng sử dụng cho mô hình ngôn ngữ mặt nạ, dự đoán câu tiếp theo, v.v. và có thể Fine-tuning (tinh chỉnh) cho các tác vụ cụ thể.
1) Ngữ cảnh hai chiều (Bidirectional Context): Không giống như các mô hình ngôn ngữ hiện có, khả năng đọc hiểu ngôn ngữ có thể được cải thiện bằng cách hiểu ngữ cảnh thông qua việc xem xét tất cả các từ đặt trước và sau chúng.
2) Mô hình ngôn ngữ mặt nạ (Masked Language Modeling, MLM): Học cách tạo ra các diễn đạt chính xác bằng cách·ẩn đi một số từ nhất định trong câu đầu vào và dự đoán từ gốc là gì bằng cách xem xét ngữ cảnh.
3) Dự đoán câu tiếp theo (Next Sentence Prediction, NSP): Bằng cách học các câu có thể xuất hiện liên tiếp thông qua việc nhập câu theo cặp, mô hình có thể hiểu ngữ cảnh ở cấp độ câu, vượt ngoài cấp độ từ.
4) Tinh chỉnh theo công việc cụ thể (Task-specific Fine-tuning): Sau khi được đào tạo trước, nó có thể được tinh chỉnh với dữ liệu liên quan đến công việc cụ thể để thực hiện nhiều quá trình xử lý ngôn ngữ tự nhiên khác nhau như phân tích cảm xúc, Q&A và nhận dạng thực thể có tên (Named-Entity Recognition, NER).
Các mô hình dòng BERT đã được cải thiện về kích thước mô hình, số lượng tính toán và tính năng bằng cách sửa đổi phương pháp học tập dựa trên phương pháp luận BERT bao gồm RoBERTa (Robustly Optimized BERT Pretraining Approach; do Meta phát triển), DistillBERT (Distilled version of BERT; do HuggingFace phát triển), ALBERT (A Lite BERT; do Google phát triển), ELECTRA (Efficiently Learning an bộ mã hóa that Classifies Token Replacements Accurately; do Google phát triển), v.v
GPT(Generative Pre-trained Transformer)
GPT(Generative Pre-trained Transformer) : GPT (Generative Pre-trained Transformer): Đây là mô hình Transformer được OpenAI đào tạo trước để thực hiện nhiều tác vụ khác nhau với lượng dữ liệu lớn.Giống như BERT, các mô hình được đào tạo trước có thể được tinh chỉnh để thực hiện tốt các công việc cụ thể.GPT có thế mạnh trong việc tạo câu vì nó học và dự đoán khi di chuyển theo một hướng.Sau khi một từ được tạo phù hợp với ngữ cảnh được xác định dựa trên các từ trước đó, từ được tạo ra cũng được phản ánh trong việc hiểu ngữ cảnh và quá trình tạo từ tiếp theo dựa trên thông tin ngữ cảnh được cập nhật sẽ diễn ra lặp đi lặp lại.Quá trình này đảm bảo rằng các câu được tạo ra sẽ duy trì một ngữ cảnh nhất quán.
| Phân loại | BERT | GPT |
|---|---|---|
| Đặc điểm | Bởi vì nó học trong khi xem xét ngữ cảnh theo cả hai hướng, tức là bên trái và bên phải của từ trong toàn bộ câu, nên ý nghĩa của câu được hiểu một cách toàn diện. Nó có thế mạnh trong các công việc xử lý ngôn ngữ tự nhiên, trong đó việc hiểu nghĩa của từ trong ngữ cảnh là rất quan trọng. | Bởi vì nó học bằng cách dự đoán từ tiếp theo khi di chuyển theo một hướng nên nó tạo ra các câu một cách tuần tự và nhất quán. Nó có thế mạnh trong tác vụ tương tác nhờ sử dụng một ngôn ngữ nhất quán và có tính liên quan cao giống như con người. |
| Ứng dụng chính | Phân loại văn bản Phân tích cảm xúc Nhận diện tên cá thể Q&A Dịch máy |
Hoàn thành câu văn Tóm tắt Chatbot đối thoại Viết sáng tạo (tiểu thuyết, thơ, v.v.) Viết mã lập trình |
GPT 시리즈 : Các loại GPT: Hiện tại có 5 phiên bản GPT do OpenAI phát triển tồn tại (GPT-1, GPT-2, GPT-3, GPT-3.5, GPT-4). Về cơ bản chúng đều có cấu trúc giống nhau, nhưng khi phiên bản tăng lên, số lượng tham số (Parameter) cũng tăng lên.Lúc này, các tham số đề cập đến trọng số (Weight) và độ lệch (Bias) được cấp cho các giá trị đầu vào trong khi học thông tin đầu vào thông qua cấu trúc thần kinh nhân tạo nhiều lớp tạo nên Transformer. Khi so sánh với bộ não con người, thì tham số cũng giống như các thông tin mà các khớp thần kinh (khe synapse) - nơi kết nối các nơ-ron trong mạng lưới thần kinh, mang theo để dẫn truyền các chất thần kinh. Khi quá trình học tập tiến triển, các tham số này được điều chỉnh để tạo ra các câu gần với câu trả lời đúng hơn. Khi số lượng tham số tăng lên, quá trình đào tạo phức tạp hơn diễn ra và khả năng hiểu các câu dài hoặc xử lý các nhiệm vụ phức tạp cũng tăng lên.
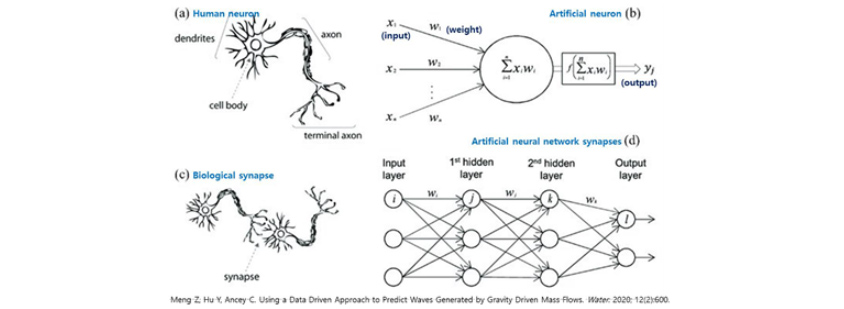 [Hình 4] Nơ-ron trí tuệ nhân tạo - con người
[Hình 4] Nơ-ron trí tuệ nhân tạo - con người
- dendrites/axon/cell body/terminal axon
- X1(input),X2,X3 -> W1,W2,W3(weight) -∑X1W1 - ∫(∑X1W1) ->Y∫(output)
- unsupervised learning
- synapse
- Input layer/1st hidde layer/2nd hidden layer/Output layer
- i ->(W1) - J ->(w2)- k -> i ->
Tính năng của GPT đã được cải thiện theo từng phiên bản và từ GPT-3, nó bắt đầu được đánh giá là thể hiện kỹ năng ngôn ngữ gần giống với con người. Trong GPT-3.5, Học tăng cường dựa trên phản hồi của con người (Reinforcement Learning with Human Feedback, sau đây gọi là RLHF) đã được áp dụng. Việc này được thực hiện bằng cách cho học các câu hỏi và câu trả lời do con người viết ra, sau đó khi mô hình tạo ra nhiều câu trả lời cho một câu hỏi nhất định, con người sẽ xếp hạng chúng và thực hiện việc đào tạo bổ sung, dẫn đến việc tạo ra các câu trả lời đáp ứng được ý định và nhu cầu của người dùng. Nói cách khác, con người đã can thiệp trong khi cho GPT học và đưa ra hướng dẫn bằng cách khen thưởng những câu trả lời đúng và phạt những câu trả lời sai, từ đó cải thiện hiệu suất của những câu trả lời được tạo ra cuối cùng. ChatGPT là mô hình tương tác được phát triển dựa trên GPT-3.5
| Các loại GPT | Tháng, năm phát hành | Số lượng tham số (cái) | Đặc điểm |
|---|---|---|---|
| GPT-1 | Tháng 6 năm 2018 | 117 triệu | - Phương thức học tập: Unsupervised pre-training with - Dữ liệu đào tạo chính: BookCrawl - Phương thức học tập: Unsupervised pre-training with unlabeled data and Supervised fine-tuning with labeled data - Fine-tuning luôn cần thiết cho một nhiệm vụ cụ thể và nhạy cảm với dữ liệu đào tạo. |
| GPT-2 | Tháng 2 năm 2019 | 1 tỷ 542 triệu | - Dữ liệu đào tạo chính: WebText (8 triệu văn bản, dung lượng 40 GB) - Phương thức đào tạo: Unsupervised Pre-training and Zero shot Learning - In-context-learning (chèn text input cho task vào mô hình học trước), một loại thuộc học tăng cường (meta-learning) |
| GPT-3 | Tháng 6 năm 2020 | 175 tỷ | - Dữ liệu đào tạo chính: CommonCrawl (Web, e-book, wiki, v.v. 753,4 GB) - Phương thức đào tạo: Unsupervised Pre-training and Zero shot, One shot, Few shot Learning - Có thể soạn thảo, viết code, biên dịch, tóm tắt giống con người - Gián tiếp hướng dẫn mô hình thông qua các ví dụ |
| GPT-3.5 | Tháng 11 năm 2022 | 175 tỷ | - Tăng nhanh độ chính xác và độ ổn định của câu trả lời bằng cách áp dụng Học tăng cường dựa trên phản hồi của con người (Reinforcement Learning with Human Feedback, RLHF) - Không giống như GPT-3, chỉ thị được đưa ra trực tiếp dưới dạng hội thoại. |
| GPT-4 | Tháng 3 năm 2023 | Không công khai | - Không công khai cấu tạo/kích cỡ mô hình, thông tin phần cứng, dữ liệu và phương pháp mô hình học - Chức năng đa phương thức (multimodal) cũng có thể nhận đầu vào hình ảnh |
Theo cách này, mô hình ngôn ngữ cuối cùng là một kho lưu trữ thông tin và là kết quả của các kho được thiết kế và đào tạo tốt kể từ thời điểm thông tin được lưu trữ để thông tin có thể được xuất ra ở dạng mong muốn. Dữ liệu được lưu trữ trong kho càng nhiều và đa dạng thì phạm vi kiến thức đầu ra từ kho càng rộng hơn. Một mô hình được đào tạo dựa trên dữ liệu có quy mô rất lớn, không thể so sánh với khối lượng học tập của các mô hình AI cũ, được gọi là Mô hình ngôn ngữ lớn (Large Language Model, LLM) và trong trường hợp của mô hình GPT-3, chi phí đào tạo ước tính là 46 triệu USD (khoảng 50 tỷ KRW). Ngoài OpenAI, nhiều công ty trong và ngoài nước đang đầu tư hàng tỷ, hàng chục tỷ để phát triển và ra mắt các mô hình ngôn ngữ lớn, người dùng cá nhân/doanh nghiệp có thể tinh chỉnh dựa trên các mô hình này bằng dữ liệu bổ sung (kiến thức ngành, thông tin thực tế, v.v.) để có thể phát triển hoặc sử dụng dịch vụ theo mục đích mong muốn của mình.
ChatGPT
ChatGPT(GPT-3.5) : Ra mắt lần đầu tiên dưới hình thức đối thoại vào tháng 11 năm 2022 dựa trên mô hình GPT-3.5.Nguyên tắc kỹ thuật cốt lõi cho phép ChatGPT thực hiện các cuộc trò chuyện gần giống con người là “Transformer”, tương ứng với chữ “T” trong GPT và nó theo dõi mối quan hệ giữa các từ trong câu để học ngữ cảnh và ý nghĩa.Khả năng ghi nhớ những gì đã nói trước đó và sửa lỗi là tính năng nổi bật nhất của nó so với các AI khác và nó cho phép trò chuyện gần giống với con người hơn so với các chatbot AI hiện có.Nó cung cấp nhiều chức năng bao gồm các câu hỏi đơn giản, tóm tắt các khái niệm khó, viết code và viết văn.
ChatGPT(GPT-4) : ChatGPT đã được nâng cấp dựa trên mô hình GPT-4 vào tháng 3 năm 2023.Giống như các mô hình ngôn ngữ khác, GPT-4 là mô hình dựa trên Transformer được đào tạo trước (Pre-trained) để dự đoán token tiếp theo trong tài liệu.Mặc dù OpenAI không tiết lộ số lượng tham số nhưng nó được cho là tạo nên từ nhiều tham số hơn GPT 3.5.Nó không chỉ vượt trội về khả năng hiểu và tạo văn bản ngôn ngữ tự nhiên một cách sáng tạo trong các tình huống phức tạp và tinh vi hơn mà khả năng tạo ra các ngôn ngữ khác ngoài tiếng Anh cũng được cải thiện nhờ học dữ liệu ngôn ngữ đa dạng hơn so với GPT-3.5 hiện có.Trên hết, một trong những điểm mạnh của GPT-4 là sự tích hợp tính năng đa phương thức (khả năng học hỏi và tư duy bằng cách nhận đồng thời thông tin qua nhiều kênh như thị giác/thính giác, tương tự như cách con người nhật thức sự vật) giúp nhận dạng hình ảnh đầu vào.Ví dụ: Bạn có thể nhận được đề xuất về các món ăn có thể nấu bằng cách sử dụng ảnh chụp thực phẩm bên trong tủ lạnh.
GPT-3.5 và GPT-4: GPT-4 nằm trong top 10% điểm cao nhất không chỉ trong kỳ thi LSAT, SAT, v.v., mà còn trong kỳ thi UBE (Uniform Bar Exam, kỳ thi luật sư Mỹ), vượt qua GPT-3.5, chỉ đạt điểm nằm trong top 10% điểm thấp nhất. Ngoài ra, GPT-4 đạt điểm (điểm đo lường trình độ ngôn ngữ với 57 câu hỏi trắc nghiệm) cao hơn trong bài kiểm tra MMLU (Measuring Massive Multitask Language Understanding, Hiểu các ngôn ngữ đa nhiệm quy mô lớn) bằng các ngôn ngữ khác ngoài tiếng Anh (kể cả tiếng Latin, tiếng Swahili, v.v. có lượng dữ liệu rất nhỏ) và đạt điểm cao hơn bài kiểm tra tiếng Anh của GPT-3.5.
▶ Nội dung này là tác phẩm được bảo vệ bởi luật bản quyền và bản quyền thuộc về người đóng góp.
▶ Nội dung tương ứng không được phép biên tập lần 2 hoặc sử dụng cho mục đích thương mại mà không có sự đồng ý trước.

Chuyên gia phân tích/trí tuệ nhân tạo
- Ưu điểm và điểm cần cân nhắc khi sử dụng đa nền tảng đám mây
- Hiện đại hóa kỹ thuật số, sáng kiến chiến lược cho doanh nghiệp tương lai bền vững
- Các vấn đề và giải pháp thực tế trong bảo mật đám mây
- Nền tảng đám mây có thực sự cần thiết không? Mối lo ngại và sự thật
- Digital Twin (Bản sao kỹ thuật số) cho đổi mới sản xuất