[Technology Toolkit 2021]
데이터 줄게, 레이블링 (해)다오∼ Auto Labeling!

Technology Toolkit 2021은 삼성SDS 연구소에서 연구개발 중인 주요 기술들을 설명하는 기술 소개서입니다.
AI,
Blockchain, Cloud, Security 기술 분야의 총 7개 기술에 대해서 각각 기술 정의, 주요 기능, 차별화 포인트 및 Use Cases를 소개하여 독자 여러분께 인사이트를 제공하고자 합니다.
Auto Labeling(자동 레이블링)
1. 기술 소개
기술 동향 및 배경
AI 기술이 발달하면서 AI 서비스에 대한 수요가 많아지고 있습니다. AI 서비스를 개발하는 과정에는 수많은 작업이 필요합니다. 예를 들면, 학습을 위한 정답지를 만들고, 학습 효율성이 높은 모델을 찾아야 하는
작업이 있습니다. 전체 작업 중 한 과정이라도 소홀히 진행한다면 AI 기술의 성능을 기대할 수 없기 때문에, 연구자와 개발자는 수작업으로 진행하는 경우가 많습니다. 여러 과정 중에서 가장 기본적이면서 노동력을
집중하는 작업은 단연 데이터에 대한 정답지를 만드는 레이블링입니다.
![[그림 1] 레이블링](https://image.samsungsds.com/kr/insights/auto_labeling_img01.jpg?queryString=20220616102005) [그림 1] 레이블링
[그림 1] 레이블링
AI 모델의 성능은 학습에 사용하는 데이터의 양이 많을수록 좋아지는 경향이 있기 때문에, 레이블이 있는 수많은 데이터가 필요합니다. 그런데 수십만, 수백만 개의 데이터를 수작업으로 레이블링하는 것은 엄청난
노동력과 시간이 필요합니다. 또한 잘못된 레이블이 있으면 AI 모델의 성능에 악영향을 미치기 때문에, 레이블이 정확한지 검토하는 과정도 필요합니다. 이러한 레이블링의 번거로움 때문에 수작업을 줄일 수 있는 기술에
대해 시장 수요가 커지고 있습니다. Amazon, IBM, Microsoft 등 글로벌 기업과 스타트업들이 참여하고 있는 자동 레이블링 기술에 대해 소개하고, 수많은 연구자와 개발자들의 레이블링에 대한 수고를 덜
수 있도록 지원하고자 합니다.
기술 정의
레이블링이란 주어진 데이터에 정답지를 만들어주는 작업이고, 이때 정답지를 레이블이라고 합니다. 딥러닝(Deep Learning)에서 지도학습(Supervised Learning)을 하는 경우, 주어지는 데이터에
대해 레이블이 있어야 합니다. 또한 부정확한 레이블로 학습을 하게 되면 모델의 성능이 떨어지기 때문에, 정확한 레이블링이 매우 중요합니다.
레이블링이 필요한 딥러닝 기술은 이미지 처리, 자연어 처리 등 매우 많습니다. 그중에서 이미지 분류, 객체 검출, 이미지 분할과 텍스트 분석에 대한 레이블링을 소개하고, 이에 적용하는 액티브 러닝 기술이 무엇인지
간략하게 살펴보겠습니다.
① 컴퓨터 비전(Computer Vision; CV)
• 이미지 분류(Image Classification)
이미지 분류의 목적은 여러 클래스가 주어졌을 때, 각 이미지가 어떤 클래스에 속하는지 분류하는 것입니다. 예를 들어, 수십만 장의 개, 고양이 이미지가 주어지고 이 이미지들을 개와 고양이로 분류하는 작업이 있다고
했을 때, 개와 고양이가 주어진 클래스이고, 개 이미지를 “개”라는 클래스로 분류하고, 고양이 이미지를 “고양이”라는 클래스로 분류하는 작업이 이미지 분류입니다.
이미지 분류에서 필요한 레이블링은 각 이미지를 주어진 클래스 중에서 알맞은 클래스로 분류하여 레이블을 만드는 것입니다. 주로 한 이미지당 하나의 레이블을 할당하지만, 작업에 따라 한 이미지가 여러 클래스에 속할
수도 있기 때문에 한 이미지에 여러 레이블을 할당하는 경우도 있습니다.
![[그림 2] 이미지 분류](https://image.samsungsds.com/kr/insights/auto_labeling_img02.jpg?queryString=20220616102005) [그림 2] 이미지 분류(출처: Pixabay)
[그림 2] 이미지 분류(출처: Pixabay)
• 객체 검출(Object Detection)
객체 검출의 목적은 여러 클래스가 주어졌을 때, 각 이미지 내에 주어진 클래스에 속하는 객체를 모두 찾는 것입니다. 예를 들면, 강아지, 고양이 이미지에서 강아지와 고양이를 검출하는 작업이 있다고 했을 때,
강아지와 고양이가 주어진 클래스이고, 이미지 내의 모든 강아지와 고양이를 찾아 표시하는 작업이 객체 검출입니다. 객체 검출에서 필요한 레이블링은 각 이미지 내에 주어진 클래스에 속하는 모든 객체의 위치와 알맞은
클래스를 할당하는 것입니다.
![[그림 3] 객체 검출](https://image.samsungsds.com/kr/insights/auto_labeling_img03.jpg?queryString=20220616102005) [그림 3] 객체 검출(출처: Pixabay)
[그림 3] 객체 검출(출처: Pixabay)
• 이미지 분할(Image Segmentation)
이미지 분할을 크게 의미론적 분할(Semantic Segmentation)과 인스턴스 분할(Instance Segmentation)로 나눌 수 있습니다. 의미론적 분할은 이미지 내의 각 픽셀(Pixel)이 주어진
클래스 중 어떤 클래스에 속하는지 분류하는 것입니다. 인스턴스 분할은 이미지 내에서 주어진 클래스에 속하는 객체를 찾고, 해당 객체에 해당하는 픽셀을 표시하는 것입니다. 예를 들면, 들판 위에 세 마리의 강아지가
나란히 겹쳐져 있는 사진이 주어졌다고 했을 때, 세 마리의 강아지를 구분하지 않고 각 픽셀에 모두 “강아지”라고 표시하는 것이 의미론적 분할이고, 세 마리의 강아지를 모두 구분하면서 각
픽셀에 “강아지-1”, “강아지-2”, “강아지-3”이라고 표시하는 것이 인스턴스 분할입니다.
의미론적 분할에서 필요한 레이블링은 이미지 내 각 픽셀을 알맞은 클래스로 분류하는 것이고, 인스턴스 분할에서 필요한 레이블링은 이미지 내 주어진 클래스에 속하는 모든 객체의 픽셀과 알맞은 클래스를 할당하는
것입니다.
![[그림 4] 의미론적 분할(좌), 인스턴스 분할(우)](https://image.samsungsds.com/kr/insights/auto_labeling_img04.jpg?queryString=20220616102005) [그림 4] 의미론적 분할(좌), 인스턴스 분할(우) / 출처: Pixabay
[그림 4] 의미론적 분할(좌), 인스턴스 분할(우) / 출처: Pixabay
② 자연어 처리(Natural Language Processing; NLP)
• 개체명 인식(Named Entity Recognition)
개체명 인식의 목적은 문장에서 미리 정해놓은 개체들을 추출하는 것입니다. 즉, 특정 단어가 미리 정해진 개체에 속하는지 아닌지 분류하는 것입니다. 예를 들면, “철수가 학교에 간다.”라는
문장이 있을 때, “철수”는 “사람 이름”, “학교”는 “장소”로 분류하는 것이 개체명 인식입니다. 개체명 인식에서 필요한
레이블링은 문장 내에서 단어에 알맞은 개체명을 할당하는 것입니다.
• 의도 분류(Intent Classification)
의도 분류의 목적은 문장의 의도를 분류하는 것입니다. 예를 들면, “아메리카노 한 잔 주세요.”라는 문장이 있을 때, 이 문장이 “구매”의 의도가 있다는 것으로 분류하는
것이 의도 분류입니다. 의도 분류에서 필요한 레이블링은 각 문장에 알맞은 의도를 할당하는 것입니다.
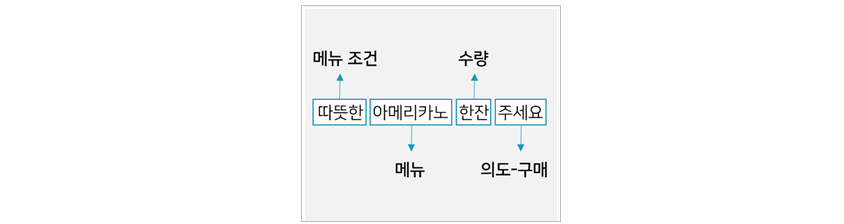 [그림 5] 의도 분류
[그림 5] 의도 분류
• 액티브 러닝(Active Learning)
액티브 러닝은 레이블링이 되어 있지 않은 데이터 세트가 있을 경우 더욱 빠르게 높은 성능의 딥러닝 모델을 만들기 위하여 시작됐습니다. 액티브 러닝 방법론은 레이블이 없는 데이터 세트를 연구개발자가 전부 레이블링할
때까지 기다리지 않습니다. 딥러닝 모델의 현 상태에서 주어진 데이터 세트에 대하여 판단해 보고, 가장 판단하기 어려운 일부 데이터를 연구개발자에게 제시합니다. 그러면 연구개발자는 해당 데이터를 우선하여
레이블링하고, 모델은 새롭게 레이블링된 데이터를 포함하여 학습을 진행합니다. 그리고 다시 학습한 상태에서 주어진 데이터 세트에 대하여 판단해 보고, 가장 판단하기 어려운 일부 데이터를 연구개발자에게 제시하는
방식으로 반복하여 진행합니다. 딥러닝 모델이 판단하기 어려웠던 데이터를 먼저 보강했기 때문에, 더 빠르게 높은 성능의 모델을 얻을 수 있게 됩니다.
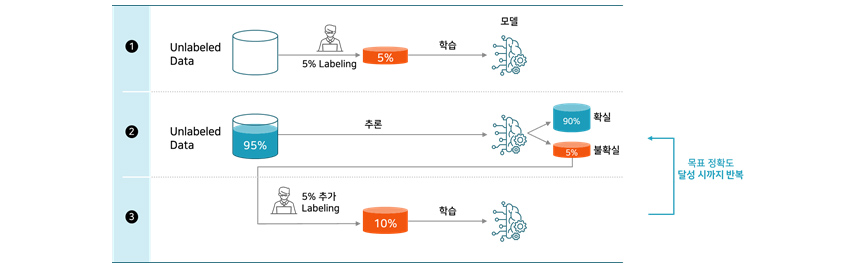 [그림 6] Active Learning
[그림 6] Active Learning
2. 주요 기능
자동 레이블링은 주요 데이터를 선택적으로 레이블링하여 모델을 학습하는 지능형 과정을 통해서 학습 데이터에 대한 레이블을 빠르게 생성할 수 있도록 지원하는 비즈니스 솔루션입니다. 레이블링되지 않은 데이터 중
소량의 데이터를 수동 레이블링하고, 레이블 정보와 다른 레이블이 있는 데이터를 함께 학습하여 나머지 데이터의 레이블을 빠르게 생성합니다. 레이블을 판단하기 어려운 데이터는 다시 수동 레이블링을 하고, 확실한
데이터는 자동 레이블링함으로써 자동화된 레이블링 프로세스를 제공합니다.
수동 레이블링
수동 레이블링은 연구개발자가 레이블링에 개입하여 데이터에 대한 레이블을 만드는 것입니다. 이 과정을 통해서 생성된 레이블은 일반적으로 확정된 레이블입니다. 자동 레이블링은 수동 레이블링을 더욱 쉽고 빠르게
레이블링할 수 있는 레이블링 전용툴을 제공합니다.
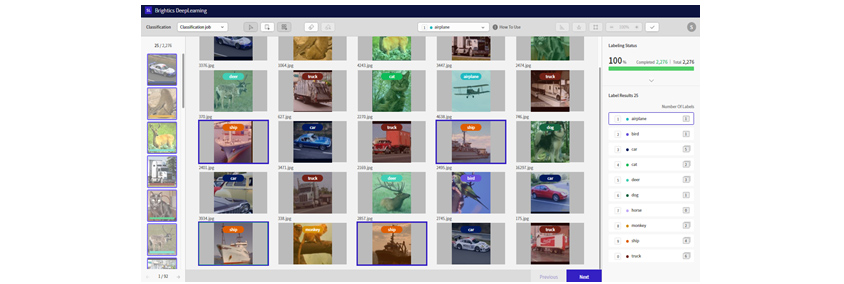 [그림 7] 수동
레이블링 화면
[그림 7] 수동
레이블링 화면
자동 레이블링
자동 레이블링은 딥러닝 모델을 통해서 예측한 레이블을 의미합니다. 이 과정을 통해서 생성한 레이블은 확정된 레이블이 아닙니다. 이렇게 예측된 레이블은 준지도학습(Semi-supervised Learning)과
같이 예측된 레이블을 이용하는 학습에 사용하거나, 수동 레이블링을 더욱 쉽게 해주기 위한 용도로 사용합니다. 자동 레이블링은 적은 양의 레이블링 데이터를 이용하여 레이블링되지 않은 데이터를 자동으로
레이블링합니다.
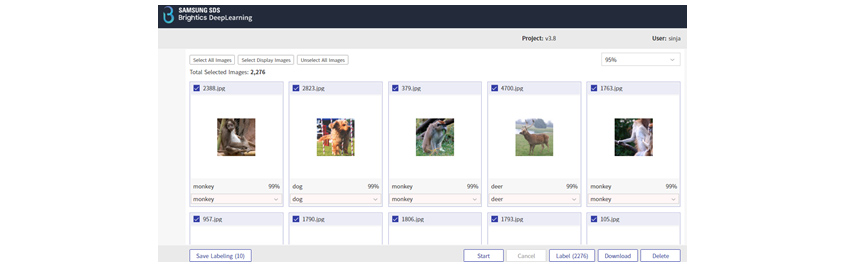 [그림 8] 자동 레이블링 화면
[그림 8] 자동 레이블링 화면
자동 리뷰(Auto Review)
자동 리뷰는 이미 레이블링된 데이터를 분석하여 기존의 레이블을 분리하거나 통합하는 과정을 통해 데이터의 질을 향상하고 학습 성능을 높이는 데 사용합니다.
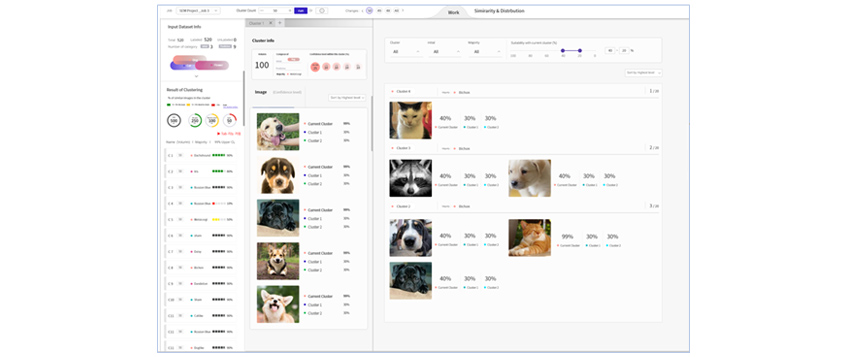 [그림 9] 자동
리뷰
[그림 9] 자동
리뷰
레이블 매니저(Label Manager)
다수의 사람이 협업하여 많은 양의 레이블을 생성할 경우, 레이블 매니저를 이용하면 레이블을 효율적으로 생성할 수 있습니다. 관리자는 레이블을 생성하는 워커를 그룹으로 지정하여 레이블 생성 Job을 생성합니다.
Job이 생성되면 레이블 매니저는 Job의 설정에 맞춰 데이터를 그룹 워커에게 분배합니다. 관리자는 레이블 매니저를 통해서 워커의 진행 상황을 체크하고 각 워커의 레이블을 검수할 수 있습니다.
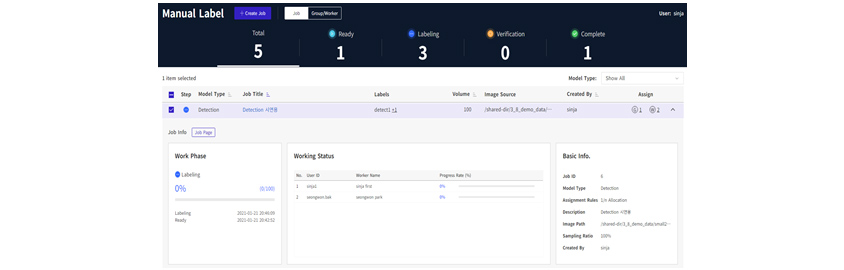 [그림 10] 레이블 매니저
[그림 10] 레이블 매니저
3. 차별화 포인트
데이터 샘플링(Data Sampling)
자동 레이블링은 완전히 레이블이 없는 상태에서부터 이미지를 샘플링합니다. 샘플링은 데이터 세트 내 레이블이 없는 이미지에서 Features를 추출하고, 자체 알고리즘을 이용하여 원하는 양의 이미지 수를
선택합니다.
a. Deep Features를 이용한 자체 데이터 샘플링 기술 보유
? 레이블이 없는 초기 상태에서 동작하는 샘플링 기술
? 랜덤 대비 약 6% 향상된 성능
b. 성능 향상을 위한 자체 학습 모델 보유
? Curriculum Learning 방식으로 수동 레이블링 이미지 추천
? 랜덤 대비 Curriculum Learning 평균 정확도 차이 4~10%
 [그림 11]
Curriculum Learning Accuracy
[그림 11]
Curriculum Learning Accuracy
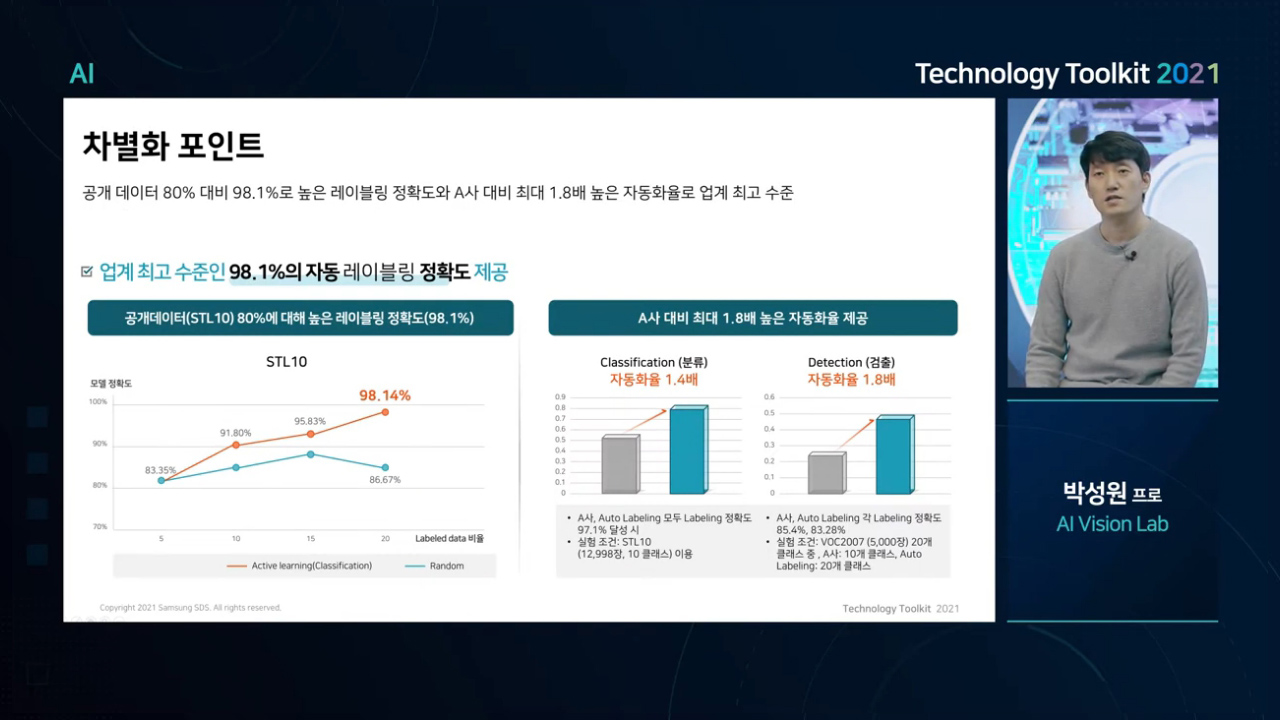
98.1%, 업계 최고수준의 자동 레이블링 정확도 제공
공개 데이터 80% 대비 98.1%로 높은 레이블링 정확도와 A사 대비 최대 1.8배 높은 자동화율로 업계 최고수준의 레이블링 성능을 제공합니다.
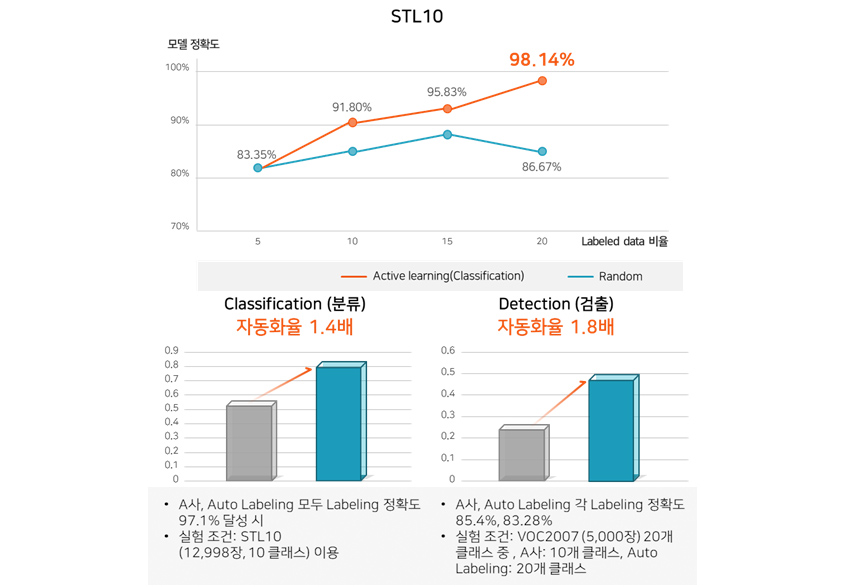
y축: 모델 정확도(%), x축: Labeled data 비율
Active Learning (Classification)
| Labeled data 비율 | 모델 정확도 | |
|---|---|---|
| Active Learning | Random | |
| 5 | 83.35% | 83.35% |
| 10 | 91.80% | 약 85% |
| 15 | 95.83% | 약 89% |
| 20 | 98.14% | 86.67% |
- A사, Auto Labeling 모두 Labeling 정확도 97.1% 달성 시
- 실험 조건: STL10 (12,998장, 10클래스)이용
- A사, Auto Labeling 각 Labeling 정확도 85.4%, 83.28%
- 실험 조건: VOC2007(5,000장) 20개 클래스 중, A사: 10개 클래스, Auto Labeling: 20개 클래스
4. Use Case
제조 현장의 Defect 분류
휴대폰 외관, 반도체 웨이퍼 불량 검사에 자동 레이블링을 사용할 수 있습니다. 외관 불량 이미지 분류를 위해 자동으로 레이블링 작업을 수행하여 시간/비용을 절감할 수 있습니다. 자동차 제조 공정 중 발생하는
도장의 외관 불량 검사에 자동 레이블링을 사용하여 레이블링 데이터 세트를 빠르게 생성할 수 있습니다.
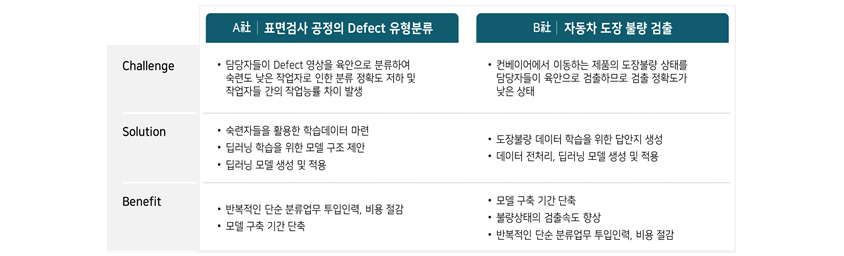
| A사: 표면검사 공정의 Defect 유형분류 | B사: 자동차 도장 불량 검출 | |
|---|---|---|
| Challenge | 담당자들이 Defect 영상을 육안으로 분류하여 숙련도 낮은 작업자로 인한 분류 정확도 저하 및 작업자들 간의 작업능률 차이 발생 | 컨베이어에서 이동하는 제품의 도장불량 상태를 담당잗들이 육안으로 검출하므로 검출 정확도가 낮은 상태 |
| Solution | 숙련자들을 활용한 학습데이터 마련 딥러닝 학습을 위한 모델 구조 제안 딥러닝 모델 생성 및 적용 |
도장불량 데이터 학습을 위한 답안지 생성 데이터 전처리, 딥러린 모델 생성 및 적용 |
| Benefit | 반복적인 단순 분류업무 투입인력, 비용 절감 모델 구축 기간 단축 |
모델 구축 기간 단축 불량상태의 검출속도 향상 반복적인 단순 분류업무 투입인력, 비용 절감 |
5. 비즈니스 사례
제조분야 사례
머리카락보다 얇은 적층세라믹커패시터(MLCC) 데이터는 레이블링에 더욱 많은 시간이 필요합니다. 자동 레이블링은 일부 데이터(20%)만 레이블링하면 남은 80%의 데이터에 대해 자동으로 레이블링하여 레이블링
시간을 절감할 수 있게 되었습니다. 또한 수동 레이블링을 진행할 때 전용 레이블링 툴을 사용하여 더욱 쉽게 많은 양의 데이터를 레이블링할 수 있었습니다.
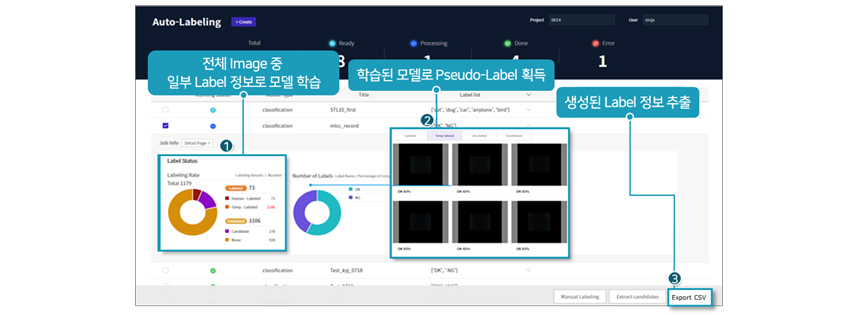 [그림 14] 비즈니스 사례 적용
화면
[그림 14] 비즈니스 사례 적용
화면
다수 기업에서 시험 적용 테스트 진행
자동 레이블링은 현재 다수의 기업에서 시험 적용과 테스트를 하며 영역을 확장하고 있습니다.
6. 맺음말
지금까지 자동 레이블링의 기술과 적용 사례를 살펴보았습니다. 딥러닝 모델 학습에 필요한 데이터를 매번 수동 레이블링하지 않는 방법을 찾는 과정에서 자동 레이블링에 관한 연구를 시작하였습니다. 2019년부터 제조
현장을 중심으로 적용하고 있고, 더 나아가 금융, 의료 등의 다양한 영역으로 적용을 확대하고 있습니다. 이에 따라 자동 레이블링을 다양한 산업에 적용하면서 현장 데이터에 대한 확보와 이해가 더욱 필요함을 실감하고
있습니다. 자동 레이블링은 더 나은 성능 향상을 위해 산업 현장과 교류하며 끊임없이 노력하여 세계 최고수준의 기술 경쟁력과 함께 시장에서의 차별성을 확보해 나갈 것입니다.
 Auto Labeling 딥러닝 기반의 레이블링 기술
Auto Labeling 딥러닝 기반의 레이블링 기술 동영상 보기
# Reference
https://www.samsungsds.com/kr/ai-dl/brightics-deep-learning.html
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.

삼성SDS 연구소 ML연구팀
Brightics DL 솔루션의 자동 레이블링, 분산학습 연구개발에 참여하였고, 현재는 AI를 위한 다양한 플랫폼 개발과 기술 연구에 참여하고 있습니다.
Technology Toolkit 2021에 소개한 기술에 대해 문의사항이 있으시거나, 아이디어, 개선사항 등 의견이 있으시면, techtoolkit@samsung.com으로 연락해 주세요.